
1 | Die Evolution verstehen: Von statischen Prompts zu dynamischen Kontexten
1.1 Was ist Prompt Engineering?
Prompt Engineering beschreibt die Kunst, eine einzelne Texteingabe („Prompt") so zu gestalten, dass ein Large Language Model (LLM) bestmöglich reagiert. Seit dem Aufkommen von GPT-3.5 haben Entwickler unzählige Stunden damit verbracht, an Formulierungen zu feilen, die Reihenfolge Prompt-Bestandteilen zu optimieren oder System-Instruktionen zu verfeinern.
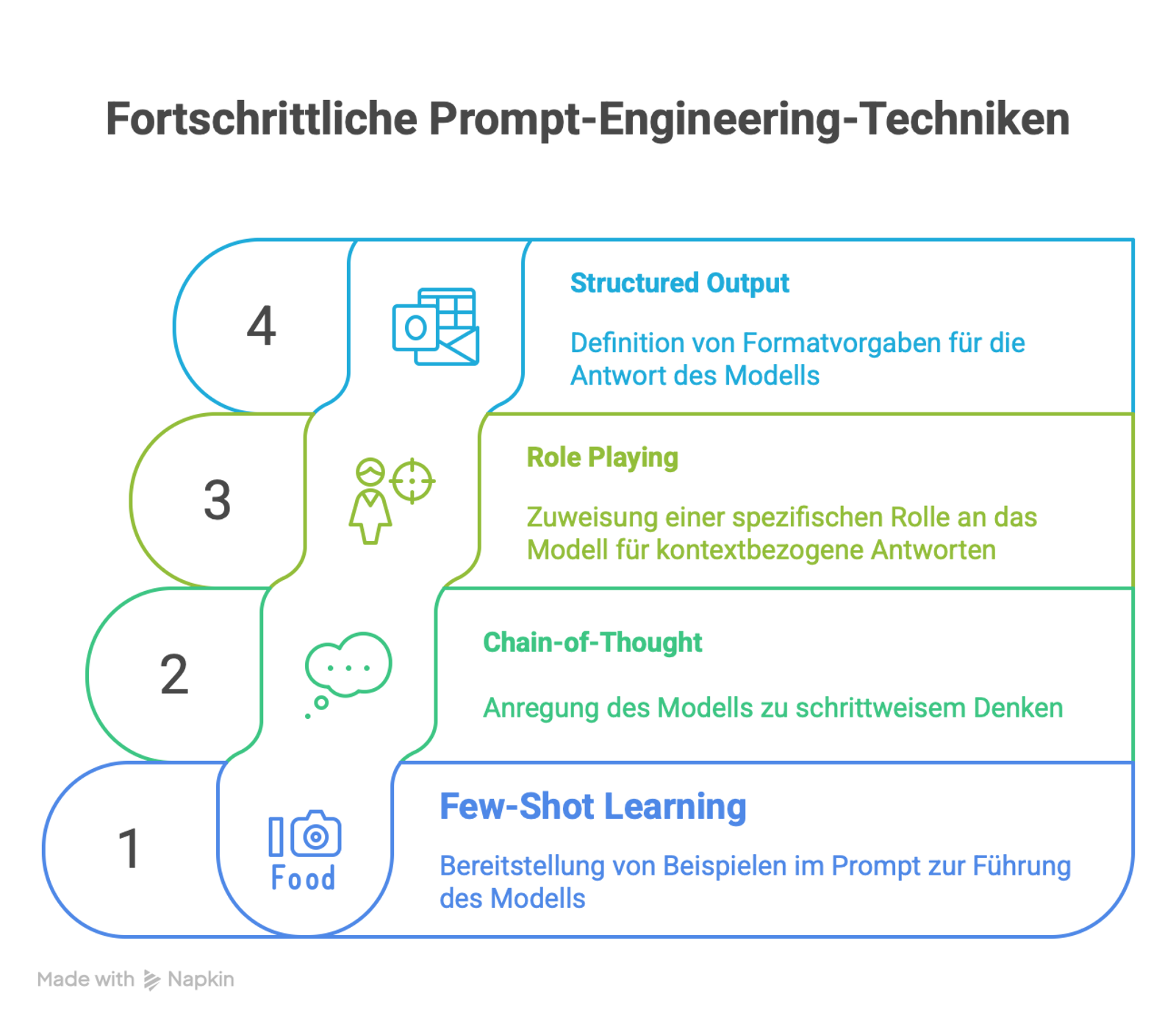
Klassische Prompt-Engineering-Techniken:
- Few-Shot Learning: Beispiele im Prompt bereitstellen
- Chain-of-Thought: Schritt-für-Schritt-Denken anregen
- Role Playing: Dem Modell eine spezifische Rolle zuweisen
- Structured Output: Formatvorgaben für die Antwort definieren
1.2 Die Erfolge und Grenzen
Prompt Engineering hat uns weit gebracht – es ermöglichte erste produktive Anwendungen von LLMs. Doch mit steigender Komplexität der Aufgaben - insbesondere beim Einbeziehen umfangreicher externer Daten wie aus Firmendatenbanken - stoßen wir an fundamentale Grenzen.
2 | Die Grenzen des reinen Prompt Engineerings
2.1 Statisch & Fragil
Ein sorgfältig optimierter Prompt funktioniert oft nur unter sehr spezifischen Bedingungen. Schon kleine Änderungen – ein anderer Nutzer mit abweichendem Sprachstil, neue Datenformate oder ein Modell-Update – können die Leistung drastisch verschlechtern. Was gestern funktionierte, versagt heute bzw. liefert keine optimalen Resultate.
2.2 Kontextfenster-Limits
Moderne LLMs haben zwar größere Kontextfenster (Claude: 200k Tokens, GPT-4: 128k Token, Gemini: 2MB), aber in der Praxis explodieren die Anforderungen schnell - insbesondere bei der Nutzung von Coding Tools wie Cursor, Windsurf, Claude Code und co.:
- Längere Konversationsverläufe
- Multiple Tool-Aufrufe mit Responses
- Umfangreiche Dokumentenanalysen
- Komplexe Code-Repositories
2.3 Fehlende Werkzeuge & Aktualität
Viele reale Aufgaben erfordern:
- Externe Wissensquellen: Unternehmensdatenbanken, APIs
- Aktuelle Informationen: Web-Suche, News-Feeds
- Aktionen: E-Mails senden, Tickets erstellen, Code deployen
Ein statischer Prompt kann diese Dynamik oft nicht abbilden.
2.4 Skalierbarkeit & Wartbarkeit
Ein clever formulierter Prompt mag für eine spezifische Aufgabe funktionieren, aber:
- Wie passt er sich an verschiedene Nutzergruppen an?
- Wie integriert er neue Features ohne Breaking Changes?
- Wie bleibt er über Modell-Updates hinweg stabil?
2.5 Beobachtbarkeit & Debugging
Ohne systematische Nachvollziehbarkeit wird Fehlersuche wie so oft in der DV zum Ratespiel:
- Warum hat das Modell diese Entscheidung getroffen?
- Welche Informationen fehlten?
- An welcher Stelle des Prozesses ging etwas schief?
3 | Der Paradigmenwechsel: Context Engineering
3.1 Die neue Definition
Laut einer prägnanten Definition von LangChain (siehe Quellen) bedeutet Context Engineering:
„Dynamische Systeme zu bauen, die dem LLM genau die richtigen Informationen und Werkzeuge in der richtigen Form zur richtigen Zeit geben, sodass es die Aufgabe zuverlässig und effizient lösen kann."
Es geht nicht mehr nur um die Eingabe, sondern um das gesamte Informationsökosystem, in dem das Modell operiert.
3.2 Warum Context > Prompt
Aktuelle Studien zeigen: Wenn KI-Agenten scheitern, liegt es in über 80% der Fälle daran, dass sie den falschen, unvollständigen, widersprüchlichen oder veralteten Kontext erhalten – nicht daran, dass das Modell selbst unzureichend wäre.
Beispiel aus der Praxis: Ein Support-Agent soll eine technische Kundenanfrage beantworten. Mit reinem Prompt Engineering würden wir versuchen, alle möglichen Szenarien im Prompt abzudecken. Mit Context Engineering:
- Analysiert der Agent den Prompt
- Prüft die Kommunikationshistorie (“Short Term Memory”)
- Lädt dynamisch relevante Dokumentation (z.B. per RAG noch vor dem LLM Aufruf)
- Prüft die Kundenhistorie (z.B. per MCP Client, “Long Term Memory“)
- Konsultiert den aktuellen System-Status z.B. per “Tool Use” bzw. “Function Calling”
- Wählt passende Response-Templates
D.h. Prompt-Engineering ist nur ein Teilaspekt des Context Engineering.
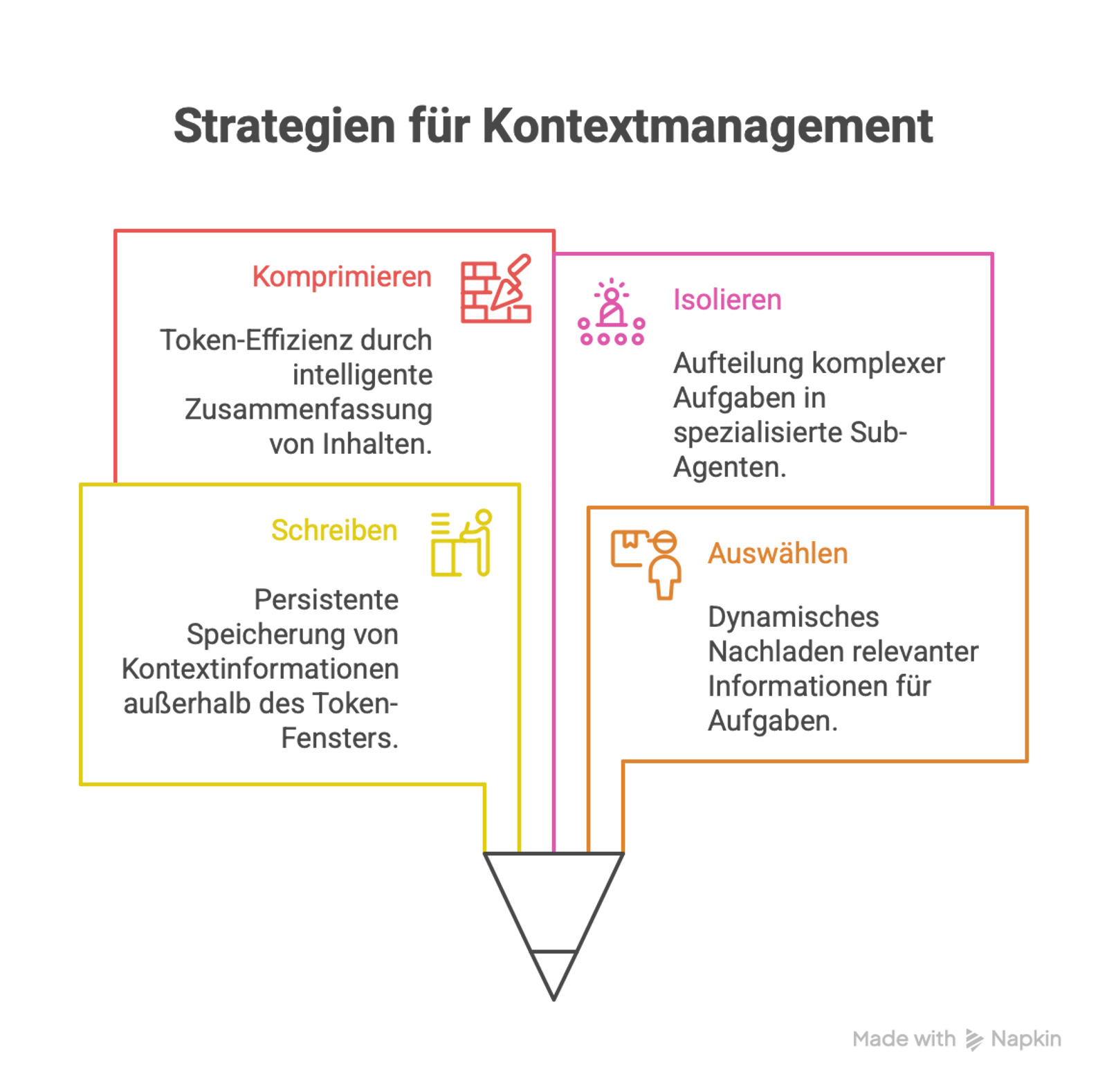
3.3 Die vier Kernstrategien des Context Engineerings
LangChain (Verweis siehe unten) identifiziert vier fundamentale Muster für effektives Context Management:
| Strategie | Zweck | Praktisches Beispiel | Implementierung |
|---|---|---|---|
| Write | Kontext außerhalb des Token-Fensters persistent speichern | Scratchpad für Zwischenergebnisse bei komplexen Berechnungen | LangGraph Memory, Redis, PostgreSQL |
| Select | Nur relevante Informationen dynamisch nachladen | Top-3 relevante Code-Snippets via Embedding-Suche | Datenbanken für schnelle, relevante Suche (z. B. Qdrant, Pinecone, Weaviate), RAG-Pipelines |
| Compress | Token-Effizienz durch intelligente Zusammenfassung | Automatische Konversations-Zusammenfassungen bei 80% Token-Auslastung (des Kontext-Fensters) | LLM-basierte Summarization, Extractive Compression |
| Isolate | Komplexe Aufgaben in spezialisierte Sub-Agenten aufteilen | Research-Agent → Analysis-Agent → Writing-Agent | Multi-Agent Orchestration, LangGraph |
4 | Best Practices für modernes Context Engineering
4.1 Empfehlungen
Hier einige Möglichkeiten, die sich (relativ) einfach nutzen lassen, um das Kontext-Fenster eines LLMs bestmöglich zu füllen:
- System- & Rollen-Instruktionen klar trennen (z. B. per YAML-Block).
- Retrieval-Augmented Generation (RAG) für aktuelle oder proprietäre Daten - z.B. Dokumentationen.
- Tool-Aufrufe deklarativ beschreiben (z.B. über JSON-Schemas), damit das Modell sie zuverlässig verwendet.
- Speicher-Schichten einführen – Kurzzeit (Thread) vs. Langzeit (User-Profil).
- Auf widerspruchsfreie Informationen achten - z.B. nicht bei Dokumentationen zu einer Programmbibliothek Versionen vermischen, so dass z.B. das LLM Zugriff auf Dokumention V-4 und V-5 gleichzeitig hat.
- Telemetry & Evals (z. B. LangSmith) nutzen, um Token-Kosten und Fehlerraten sichtbar zu machen
Hier noch einige Beispiele, welche Metriken interessant sein können:
- Context Utilization Rate: Wie viel des bereitgestellten Kontexts wird tatsächlich genutzt?
- Retrieval Precision: Waren die nachgeladenen Informationen relevant?
- Token Efficiency: Verhältnis von Information zu Token-Verbrauch
- Context Switching Overhead: Zeit für Kontext-Updates
- Error Attribution: Welcher Kontext-Teil führte zu Fehlern?
5 | Praktischer Leitfaden: Starten mit Context Engineering
Hier einige Anhaltspunkte für eine strukturierte Vorgehensweise:
Als Vorbereitung den benötigten Kontext ermitteln:
- Welche Informationen braucht dein System wirklich?
- Welche Datenquellen sind verfügbar?
- Wie aktuell müssen die Daten sein?
Welche Anwendungsfälle gibt es im Detail?
- Identifiziere die Top-5 Anwendungsfälle
- Dokumentiere den benötigten Kontext pro Use Case
- Erkenne Überschneidungen und Muster
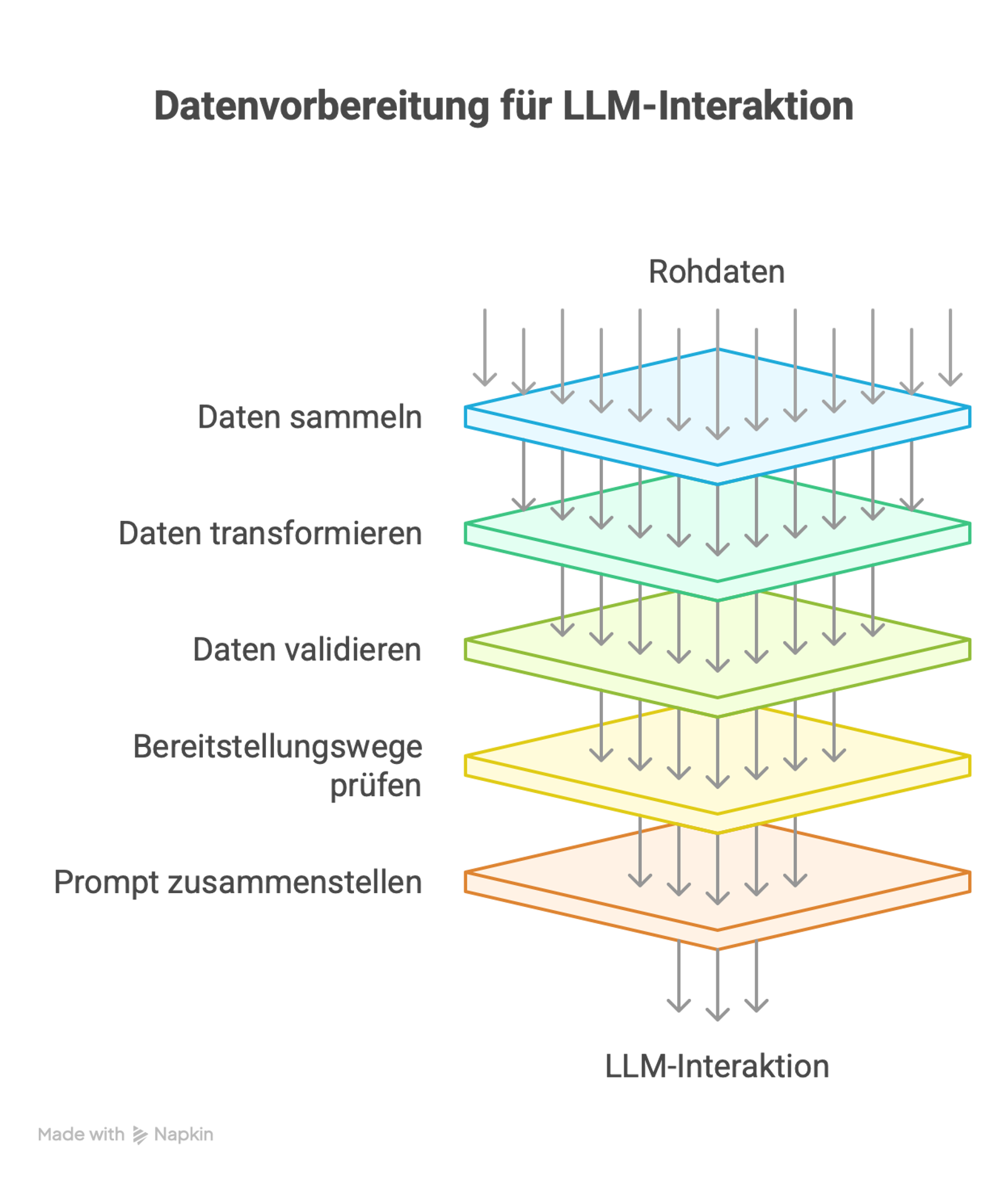
Schritte für die Implementierung:
- Relevante Daten sammeln (“collect”)
- Daten für LLM aufbereiten (“transform”)
- Auf Vollständigkeit, Korrektheit und Widerspruchsfreiheit prüfen (“validate”)
- Bereitstellungswege für die Daten prüfen - z.B. per RAG oder per MCP Server?
- Finalen Prompt / Kontext zusammenfügen (“assemble”)
Iterative Verbesserung:
Starte mit statischem Kontext
Füge schrittweise dynamische Elemente hinzu
Messe nach Möglichkeit den Impact jeder Änderung
6 | Zukunftsausblick: Wohin geht die Reise?
Aktuelle Trends sind z.B.:
- Adaptive Context Windows: Modelle, die ihr Kontextfenster dynamisch anpassen
- Multi-Modal Context: Integration von Text, Bildern, Audio, Video
- Federated Context: Verteilte Kontextquellen - aber unter Wahrung des Datenschutzes
- Self-Organizing Context: KI-Systeme, die ihren eigenen Kontext optimieren
Die aber mit einigen Herausforderungen verbunden sind:
- Context Coherence: Konsistenz über multiple Kontextquellen
- Privacy-Aware Context: DSGVO-konforme Kontext-Verarbeitung
- Real-Time Context Updates: Millisekunden-schnelle Kontext-Aktualisierung
- Cross-Model Context: Kontext-Sharing zwischen verschiedenen KI-Modellen
- usw.
7 | Fazit: Der Weg nach vorn
Prompt Engineering war der erste Schritt – es lehrte uns, wie wir mit KI-Modellen kommunizieren. Context Engineering ist der nächste evolutionäre Sprung: Es geht darum, intelligente Informationsökosysteme zu schaffen, in denen KI ihr volles Potential entfalten kann.
Die Zukunft gehört nicht dem cleversten Prompt, sondern dem smartesten Kontext-System. Unternehmen, die diesen Wandel verstehen und umsetzen, werden einen entscheidenden Wettbewerbsvorteil haben.
Die Kernbotschaft: Denke nicht mehr in einzelnen Prompts, sondern in dynamischen Kontext-Systemen. Deine KI ist nur so gut wie der Kontext, den du ihr gibst.
Hinweis: In Kürze wird's von uns einen neuen Beitrag geben, der Context Engineering in einer .NET Lösung mit MCP Servern umsetzt.
Literatur & Weiterführende Ressourcen
Primärquellen
- LangChain Blog: "The Rise of Context Engineering" (23. Juni 2025)
- LangChain Blog: "Context Engineering for Agents" (2. Juli 2025)
Ergänzende Literatur
- Anthropic Research: "Claudes Constitution" (2024)
- Mohammed Al Salboukh: "Strategies and Techniques for Managing the Size of the Context Window When Using LLM" (2024)
Hast du bereits Erfahrungen mit Context Engineering gemacht? Welche Herausforderungen siehst du in deinem Anwendungsfall? Lass es uns in den Kommentaren diskutieren!


