Pragmatischer Claude Code Einsatz für C# Entwickler auf Mac
2/20/2026
Der vorliegende Beitrag bietet eine allgemeinverständliche, nichttechnische Einführung in die Funktionsweise von Large Language Models (LLMs) und insbesondere der bekannten GPT-Modelle.
Der vorliegende Beitrag bietet eine allgemeinverständliche, nichttechnische Einführung in die Funktionsweise von Large Language Models (LLMs) und insbesondere der bekannten GPT-Modelle. Ziel dieser Einführung ist es, die grundlegenden Konzepte hinter diesen beeindruckenden KI-Technologien verständlich darzustellen, so dass auch Leser ohne technische Vorkenntnisse die Prinzipien der Sprachverarbeitung und -generierung nachvollziehen können. Dazu werden wichtige Begriffe, zentrale Komponenten wie die Transformer-Architektur und typische Herausforderungen bei der Verarbeitung natürlicher Sprache anhand eingängiger Analogien erläutert.
Disclaimer: Zur Recherche wurden AI Tools genutzt, Fotos sind (bis auf Nvidia / xAI KI) generiert. Diagramme / Übersichten / Texte sind selbst erstellt (bis auf das "offizielle" Transformer Schaubild).
Viele der notwendigen Grundlagen für Large Language Models (LLM) und Generative Pretrained Transformers (GPT) wurden bereits in den letzten 30 Jahren entwickelt, jedoch scheint die Entwicklung erst mit dem Erscheinen von GPT-3.5/ChatGPT im Jahr 2022 so richtig in der Öffentlichkeit angekommen zu sein und sich seitdem rasant weiterzuentwickeln. Daher hier eine kurze Übersicht über wichtige Entwicklungen und Grundlagen, die zusammen mit der jetzt verfügbaren leistungsfähigen Hardware zu diesem technologischen Sprung geführt haben.
In den Anfangsjahren der Computerlinguistik wurden Sprachprogramme durch fest vorgegebene Regeln und Wörterbücher gesteuert. Linguisten definierten über Regeln, wie Sätze aufgebaut sein sollten, und der Computer folgte diesen Anweisungen strikt. Das ist in etwa vergleichbar mit einem Arbeiter, der für jeden Arbeitsschritt ein starres Regelbuch hat und nicht davon abweichen und improvisieren kann. Frühe Chatbots wie ELIZA (1966) funktionierten genau nach diesem Prinzip, indem sie Benutzereingaben mit vordefinierten Mustern verglichen und entsprechende Antworten ausgaben. Solche Systeme konnten einfache Gespräche simulieren, stießen aber schnell an ihre Grenzen, sobald die Eingaben nicht mehr exakt den hinterlegten Regeln entsprachen.
Ab den 1980er Jahren setzte ein Umdenken ein - Computer lernten nun aus Beispieldaten statt nur aus hart definierten Regeln. Statistische Sprachmodelle analysieren große Textmengen und zählen, welche Wortfolgen wie oft vorkommen. Daraus ergeben sich Wahrscheinlichkeiten für die nächste Wortwahl - ähnlich einer Texterkennung im Handy, die das wahrscheinlich nächste Wort vorschlägt. Eine passende Analogie wäre ein Hobbykoch, der nach dem Ausprobieren sehr vieler Rezepte durchaus eigene passende Abläufe finden kann - ohne die späteren Konsumenten seiner Kunst zu sehr zu frustrieren. Diese n-Gramm-Modelle und verwandte statistische Verfahren wurden beispielsweise in der maschinellen Übersetzung und der Spracherkennung eingesetzt und haben im Vergleich zu früheren Lösungen zu flüssigeren Ergebnissen geführt, da sie auf echten Sprachdaten basieren.
Um die Bedeutung von Wörtern besser erfassen zu können, wurden in den 2010er Jahren Worteinbettungen eingeführt. Dabei wird jedes Wort durch einen Zahlenvektor repräsentiert, der zeigt, wie das Wort in verschiedenen Kontexten bzw. Dimensionen klassifiziert ist. Wörter mit ähnlicher Bedeutung liegen in diesem Vektorraum nahe beieinander - man kann sich das wie in einer Werkstatt vorstellen, in der ähnliche Werkzeuge (z. B. Schraubenzieher und Schraubenschlüssel) in derselben Schublade liegen, während andersartige Werkzeuge - wie ein Pinsel - weiter entfernt aufbewahrt werden. Numerisch wird das über einen ähnlichen Zahlenwert in der Dimension “Funktionalität” ausgedrückt. Ein bekanntes Beispiel ist Word2Vec (2013), bei dem der Computer lernt, dass z.B. „König“ und „Königin“ oder „Auto“ und „Fahrzeug“ in ähnlichen Kontexten vorkommen. Solche Einbettungen ermöglichen es NLP-Systemen, Bedeutungsähnlichkeiten zu erkennen und bessere Ergebnisse bei Aufgaben wie Suche, Übersetzung oder Textklassifikation zu erzielen.
Mit leistungsfähigeren Computern hielten ab den 2010er Jahren tiefe neuronale Netze Einzug in die Sprachverarbeitung. Rekurrente Neuronale Netze (RNNs) lesen einen Satz Wort für Wort und behalten einen internen Zustand bei, um sich an zuvor Gelesenes zu erinnern. Auf diese Weise können sie den Kontext der vorher gelesenen Wörter berücksichtigen - ähnlich wie ein Handwerker, der eine mehrstufige Anleitung Schritt für Schritt befolgt und sich dabei an das erinnert, was er zuvor bearbeitet hat. Ein Problem einfacher RNNs war jedoch, dass sie wichtige Informationen über längere Sätze hinweg „vergessen“ konnten. Abhilfe schaffte das Long Short-Term Memory (LSTM): Dieses erweiterte RNN aus dem Jahr 1997 besitzt eine Art Langzeitgedächtnis, das unwichtige Informationen ausfiltert und wichtige über viele Wörter hinweg speichert. Hier macht sich quasi Handwerker während der Arbeit Notizen, um später darauf zurückgreifen zu können. Dank RNNs und LSTMs können Übersetzungs- und Spracherkennungssysteme ganze Sätze sinnvoll verarbeiten, ohne nach wenigen Wörtern den Faden zu verlieren.
Ein großer Fortschritt wurde Mitte der 2010er Jahre erzielt, als Modelle lernten, sich dynamisch auf wichtige Wortbeziehungen zu konzentrieren. Der Aufmerksamkeitsmechanismus ermöglicht es einem KI-Modell, bei jedem generierten Wort zu bestimmen, welche Teile des bisherigen Textes besonders relevant sind. Man kann sich das wie einen Dirigenten vorstellen, der während eines Orchesterstücks den einzelnen Instrumentengruppen signalisiert, wann sie wichtiger sind und hervortreten sollen. In jedem Takt "hört" der Dirigent das gesamte Orchester, entscheidet aber, welche Instrumente in diesem Moment besondere Aufmerksamkeit verdienen. So spielen Substantive “lauter” als Verben und Adjektive, diese wiederum lauter als Füllwörter. Durch diese gezielte Gewichtung von Wortbeziehungen konnten beispielsweise Übersetzungsprogramme deutlich bessere Ergebnisse liefern, da das Modell bei jedem Wort die relevanten Zusammenhänge im Originalsatz berücksichtigen konnte. Der Attention-Mechanismus berechnet quasi eine "Bedeutungslandkarte" für alle Wörter im Kontext und ermöglicht so ein tieferes Verständnis sprachlicher Strukturen. Dies ebnete den Weg für die Transformer-Architektur, die durch die parallele Verarbeitung dieser Beziehungen besonders effizient arbeitet.
Mehr dazu bei der späteren Erläuterung der Arbeitsweise eines LLM mit Transformer-Architektur.
Im Jahr 2017 hat Google die NLP-Welt mit der Transformer-Architektur revolutioniert. Ein Transformer-Modell verarbeitet einen ganzen Satz auf einmal statt Wort für Wort und nutzt dabei mehrere Aufmerksamkeitsmechanismen (Self-Attention), um die Beziehungen zwischen allen Wörtern parallel auszuwerten. Bildlich gesprochen ist das wie ein komplettes Orchester, in dem nicht nur ein Dirigent, sondern jeder Musiker gleichzeitig Dirigent und Instrumentalist ist: Jedes "Instrument" (Wort) nimmt alle anderen Instrumente wahr und entscheidet selbst, welchen es seine besondere Aufmerksamkeit schenken will. So wird zum Beispiel ermittelt, welche Adjektive zu einem Substantiv gehören und welcher Bedeutungsinhalt sich dahinter verbirgt.
Während herkömmliche Modelle ein lineares Musikstück Takt für Takt abspielen, erfasst der Transformer die gesamte Partitur gleichzeitig, wobei verschiedene "Aufmerksamkeitsebenen" (Attention Heads) unterschiedliche Aspekte der Komposition hervorheben - manche konzentrieren sich auf Rhythmus, andere auf Melodie oder Harmonie. So ist das Satzfragment “Der laute Sportwagen” semantisch nahezu gleichbedeutend mit “Die röhrende Karre”, aber auf der Aufmerksamkeitsebene bzw. in der Dimension “Stil” lassen sich schon deutliche Unterschiede feststellen.
Durch diese Parallelisierung und die mehrschichtige Verteilung der Aufmerksamkeit können Transformer sehr lange Texte und komplexe Zusammenhänge effizient verarbeiten, ohne dass Informationen vom Satzanfang verloren gehen. Transformermodelle sind seither das Herzstück moderner Sprachsysteme - aktuelle Übersetzer, Sprachassistenten und Large Language Models basieren alle auf dieser Architektur.
Statt für jede neue NLP-Aufgabe ein eigenes Modell zu entwickeln, trainiert man seit etwa 2018 gewaltige Sprachmodelle zunächst auf riesigen Textsammlungen. Dabei lernt das Modell allgemeine Sprachmuster und Zusammenhänge aus Büchern, Artikeln oder dem Web - wie z.B. die gesamte Wikipedia. Anschließend kann es mit relativ wenigen Beispielen auf eine konkrete Aufgabe spezialisiert werden - man spricht vom Transferlernen. Dies ist ungefähr vergleichbar mit einem Lehrling, der zunächst alle verfügbaren Lehrbücher in der Berufsschule studiert, um die Grundlagen zu verinnerlichen, und dann mit einer spezifischer Anleitung durch den Meister sehr unterschiedliche Aufgaben bewältigen kann. Ein frühes Beispiel ist BERT von Google (2018): Dieses Modell wurde auf der englischen Wikipedia vortrainiert und konnte dann durch leichtes Feintuning viele verschiedene Sprachaufgaben bewältigen (von der Beantwortung von Fragen bis hin zu Textzusammenfassungen). Kurz darauf folgte die GPT-Serie von OpenAI. GPT-2 (2019) beeindruckte mit der Fähigkeit, aus wenigen Stichwörtern zusammenhängende Texte zu schreiben. GPT-3 (2020) ging noch einen Schritt weiter - mit 175 Milliarden Parametern (dazu später mehr) zeigte es eine erstaunliche Vielseitigkeit, die es ihm ermöglichte, Aufgaben in natürlicher Sprache mit minimalen Vorgaben zu erledigen. Solche vortrainierten großen Sprachmodelle bilden heute die Grundlage für praktische Anwendungen: ChatGPT zum Beispiel basiert auf einem vortrainierten Modell und kann so Fragen beantworten oder Unterhaltungen führen, ohne für jede einzelne Aufgabe manuell programmiert werden zu müssen.
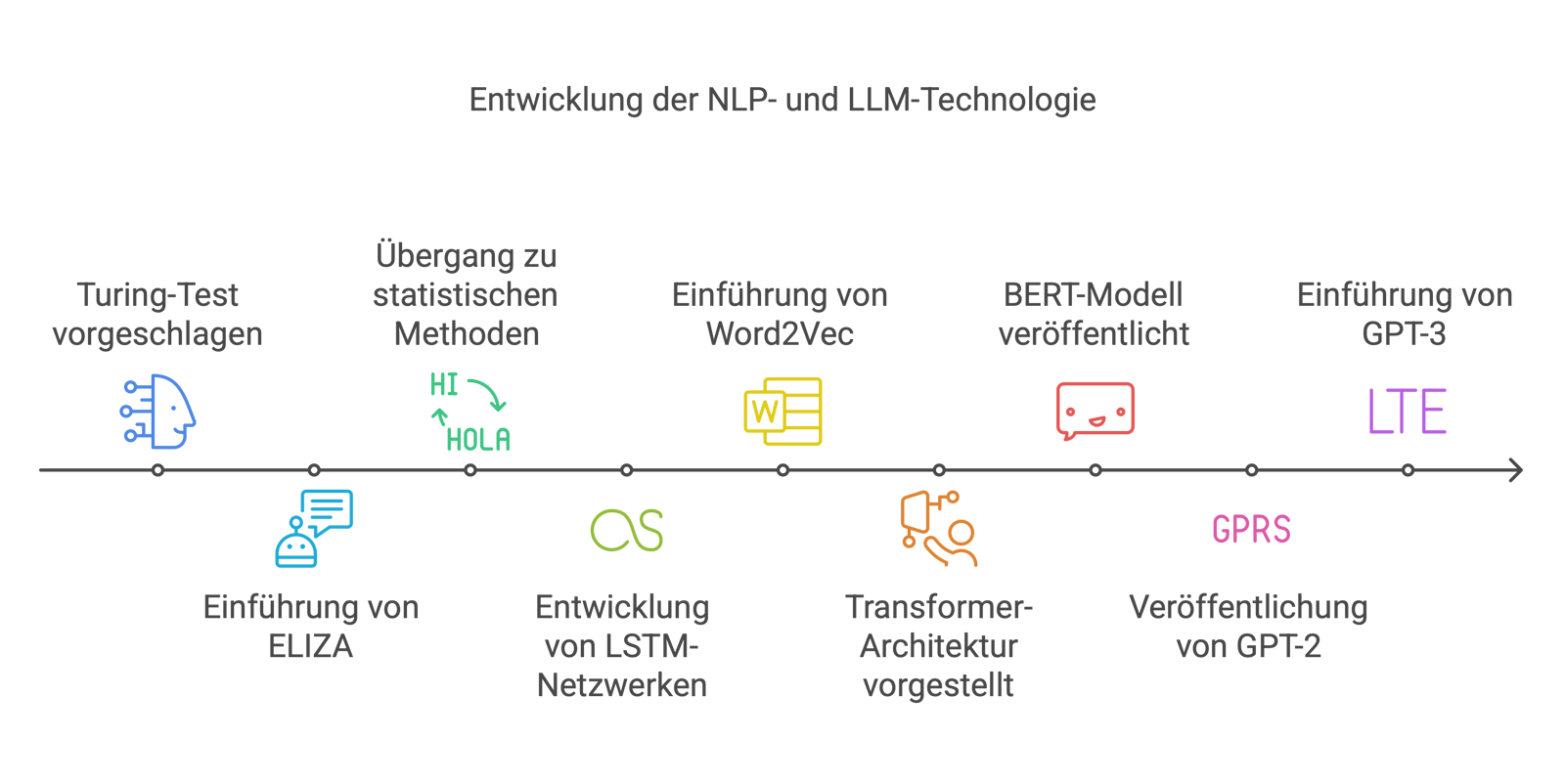
Hier zusammengefasst eine Auswahl wichtiger Meilensteine, besonders auf die Entwicklung der Sprachverarbeitung (NLP) bezogen, da diese für die aktuellen GPTs besonders wichtig ist:
|
Jahr |
Meilenstein (NLP/LLM-Entwicklung) |
|---|---|
|
1950 |
Alan Turing schlägt den Turing-Test vor – ein Kriterium dafür, ob ein Computer durch Sprachdialog menschliches Denkvermögen überzeugend nachahmen kann . |
|
1966 |
MIT-Forscher Joseph Weizenbaum präsentiert ELIZA, den ersten Chatbot. ELIZA reagiert nach einfachen Musterregeln auf Eingaben und zeigt damit, wie Computer einfache Dialoge führen können . |
|
1980er |
Übergang von rein regelbasierten Systemen zu statistischen Methoden in der Sprachverarbeitung. Computer lernen nun aus großen Textkorpora mittels Wahrscheinlichkeiten, was die Verarbeitung natürlicher Sprache deutlich verbessert . |
|
1997 |
Einführung der LSTM-Netzwerke (Long Short-Term Memory) durch Hochreiter und Schmidhuber. Diese erweiterten neuronalen Netze können sich auch an weit zurückliegende Informationen im Text erinnern und lösen damit ein zentrales Problem früherer RNNs . |
|
2013 |
Google entwickelt Word2Vec, ein Verfahren zur Erstellung von Wort-Einbettungen. Erstmals werden Wörter als Vektoren dargestellt, sodass Ähnlichkeiten in der Bedeutung rechnerisch erfasst werden können . |
|
2017 |
Google veröffentlicht das Papier „Attention is All You Need“. Darin wird die Transformer-Architektur mit Selbstaufmerksamkeit vorgestellt – ein Paradigmenwechsel, der die parallele Verarbeitung von Sprache ermöglicht . |
|
2018 |
Das vortrainierte Sprachmodell BERT (Bidirectional Encoder Representations from Transformers) wird vorgestellt. BERT nutzt den Transformer, um Worte im Kontext beidseitig zu verstehen, und läutet die Ära des Transferlernens in der Sprachverarbeitung ein . |
|
2019 |
OpenAI veröffentlicht GPT-2, ein generatives Sprachmodell mit 1,5 Milliarden Parametern. GPT-2 kann aus einer kurzen Eingabe einen langen, zusammenhängenden Text schreiben und setzt neue Maßstäbe in der Textgenerierung . |
|
2020 |
Mit OpenAIs GPT-3 (175 Milliarden Parameter) erscheint das bis dahin größte Sprachmodell. GPT-3 demonstriert, dass ein einziges Modell durch reines Vortraining vielfältige Sprachaufgaben nahezu ohne spezielle Anpassung lösen kann . |
|
2022 |
ChatGPT wird der Öffentlichkeit zugänglich. Dieses auf GPT-3.5 basierende Dialogsystem zeigt eindrucksvoll, wie weit LLM-Technologie gekommen ist, indem es in natürlicher Sprache mit Nutzern kommuniziert und komplexe Anfragen verständlich beantwortet . |
Firmen wie Nvidia haben in der Vergangenheit spezialisierte Grafikprozessoren (GPUs) entwickelt, die später auch für das Training großer Sprachmodelle optimiert wurden. GPUs eignen sich besonders gut für KI-Berechnungen, da sie eine hohe Parallelverarbeitungskapazität für Gleitkommazahlen besitzen und damit große Mengen an Matrixoperationen effizient ausführen können - eine Schlüsselkomponente sowohl beim Gaming als auch beim Training neuronaler Netze. Insbesondere die Einführung der Blackwell-Architektur im Jahr 2024 hat zu erheblichen Leistungssteigerungen geführt, die das Training und die Anwendung von LLMs effizienter machen. Darüber hinaus hat Nvidia eigene KI-Hardware wie die Hopper- und Blackwell-Chips entwickelt, die speziell für die Anforderungen von KI-Workloads optimiert sind. Diese spezialisierten Chips ermöglichen eine deutlich höhere Geschwindigkeit und Effizienz im Vergleich zu herkömmlichen GPUs. (de.wikipedia.org). Die Geschwindigkeit dieser Chips ist immens, z.B. bei Nvidias H100 Chip bis zu 1 Petaflop = 1.000 Teraflop = 1.000.000 Gigaflop (eine Million Milliarden FP32 Operationen pro Sekunde, FLOP = Floating Point Operation).

Trotzdem müssen für das effiziente Training von LLMs Tausende dieser Hochleistungskarten kombiniert werden, z.B. 100.000 für das neue xAI-Rechenzentrum “Colossus” für das LLM “Grok 3” in Boxtown, einem Vorort von Memphis, Tennessee.

Nicht nur die Anzahl der GPUs, auch andere Daten sind eindrucksvoll:
Colossus wurde in nur 122 Tagen errichtet und gilt als das größte Rechenzentrum der Welt
Die Anlage umfasst eine Fläche von etwa 69.700 Quadratmetern (750.000 Quadratfuß)
Ursprünglich startete es im September 2024 mit 100.000 NVIDIA H100 GPUs, aktuell sind es 200.000
Die Stromkapazität wurde von anfänglich 150 MW auf etwa 250 MW bis Dezember 2024 erhöht, es sind bis 1.2 Gigawatt geplant
Solche Summen, wie zum Aufbau von Rechenzentren in der Größe von Colossus sind nur von extrem finanzstarken Investoren zu stemmen. Daher haben vor allem Unternehmen wie Microsoft, Google, Meta und OpenAI große Summen in die KI-Forschung, die Entwicklung immer größerer und leistungsfähigerer Modelle und den Aufbau der notwendigen Infrastruktur investiert. Die genannten Unternehmen verfügen als Basis für Investitionen über hohe laufende Cashflows, die sich aus ihrer Verankerung in der Plattformökonomie (einfache Skalierung des Geschäftsmodells über Millionen von Nutzern) ergeben. Andere Mitspieler wie OpenAI oder Anthropic bemühen sich regelmäßig, entsprechende finanzstarke Investoren zu finden. Beispielsweise hat OpenAI im Jahr 2024 bis zu 40 Milliarden Dollar zur Entwicklung von neuen Modellen wie GPT-4.5 erhalten.

Der intensive Wettbewerb zwischen diesen Technologieunternehmen beschleunigt den Fortschritt immer weiter. Unternehmen wie xAI von Elon Musk und Meta bauen große Cluster von Nvidia-Chips, um leistungsfähigere KI-Systeme zu entwickeln. Dieser Wettlauf um die Vorherrschaft in der KI primär in den USA und China treibt die rasche Entwicklung von GPT-Modellen voran. Darüber hinaus werden weiterhin erhebliche Investitionen in die KI-Forschung getätigt.
Large Language Models (LLMs) sind große, vortrainierte neuronale Netze, die auf die Verarbeitung und Generierung natürlicher Sprache spezialisiert sind. Sie basieren in der Regel auf der Transformer-Architektur und werden mit großen Mengen von Textdaten trainiert, um vielfältige Sprachaufgaben wie Textverstehen, Übersetzen oder Zusammenfassen zu bewältigen.
GPT (Generative Pre-trained Transformer) ist eine spezielle Klasse von LLMs, die von OpenAI entwickelt wurde. Während LLM ein allgemeiner Begriff für groß angelegte Sprachmodelle ist, bezieht sich GPT auf eine spezielle Architektur innerhalb dieser Kategorie, die sich durch ein autoregressives Vorhersagemodell auszeichnet - es generiert Text, indem es Wort für Wort auf der Grundlage vorhergehender Wörter vorhersagt. GPT-Modelle sind eine Untergruppe der LLMs, aber nicht alle LLMs sind GPT-Modelle.
Die Transformer-Architektur ist das Grundmodell hinter den bekannten modernen Large Language Models (LLMs) wie ChatGPT, Gemini, Claude oder Grok. Sie besteht aus mehreren Encoder- und Decoder-Schichten, die gemeinsam darauf ausgelegt sind, komplexe sprachliche Zusammenhänge effizient zu verarbeiten.
Ein Encoder verarbeitet den Eingabetext und wandelt ihn in eine abstrakte Repräsentation aus Vektoren (Embeddings) um. Dabei erkennt er Beziehungen zwischen Wörtern, berücksichtigt Bedeutungen und strukturiert die Informationen so, dass sie für den Decoder nutzbar sind. Anstatt eine direkte Wort-für-Wort-Übersetzung zu liefern, erstellt er eine viel umfassendere Repräsentation der Eingabe, die es dem Decoder ermöglicht, eine kohärente und hoffentlich sinnvolle Antwort zu generieren.
Ein Decoder in einem KI-Sprachmodell wandelt eine interne Repräsentation von Informationen in verständlichen Text um. Er analysiert die bereits generierten Wörter, um Konsistenz und Kohärenz sicherzustellen, und nutzt die Informationen des Encoders, um relevante Inhalte korrekt wiederzugeben. Basierend auf trainierten Mustern und Wahrscheinlichkeiten entscheidet es schrittweise, welches Wort am besten als nächstes folgt, bis eine vollständige und sinnvolle Antwort entsteht.
Eine treffende Analogie ist die Zusammenarbeit zwischen einem Fachanalysten und einem Redakteur. Der Encoder übernimmt die Rolle des Analysten, der alle relevanten Informationen aus einer Quelle extrahiert, strukturiert und für die Weiterverarbeitung aufbereitet. Der Decoder agiert als Redakteur, der auf Basis dieser Analyse einen verständlichen und kohärenten Text formuliert. Durch wiederholte Verarbeitungsschritte in mehreren Schichten wird die Qualität und Genauigkeit der Ausgabe optimiert, so dass das Modell sprachlich hochwertige und kontextuell passende Antworten erzeugen kann.
Die Abbildung zeigt die klassische Enkoder-Dekoder-Architektur eines Transformers, bei der der Enkoder eine Eingabesequenz verarbeitet und eine abstrakte Darstellung erzeugt, die dann vom Dekoder zur Erzeugung einer Ausgabe verwendet wird. Ein GPT ist jedoch ein Spezialfall eines Large Language Models (LLM), das nur aus einem Decoder besteht und auf den Encoder verzichtet. Während in der klassischen Transformer-Architektur der Decoder auf die komplette Encoder-Repräsentation zugreifen kann, um Wort für Wort eine Ausgabe zu erzeugen, muss ein GPT den gesamten Verarbeitungsprozess alleine bewältigen.
Ein zentraler Mechanismus, der dies ermöglicht, ist die Masked Multi-Head Attention, die in der Grafik im Decoder-Block zu sehen ist. Dieser Mechanismus wird in GPTs verwendet, um sicherzustellen, dass jedes Token nur auf vorherige Token in der Sequenz schauen kann, nicht aber auf zukünftige Wörter. Das Modell verarbeitet Texte autoregressiv, d.h. Schritt für Schritt, indem es das nächste Token auf der Grundlage der bereits generierten Token vorhersagt. Damit unterscheidet sich ein GPT substantiell von Encoder-Decoder-Architekturen wie BERT, die über eine globale Eingabedarstellung verfügen.
Da GPT keinen Encoder besitzt, muss es den Kontext vollständig aus den bereits generierten Tokens ableiten. Jedes neue Token durchläuft erneut die mehrstufigen Self-Attention-Mechanismen, die bereits berechnete Informationen wiederverwenden, um kohärente, grammatikalisch korrekte und inhaltlich sinnvolle Sequenzen zu erzeugen. Durch diese autoregressive Struktur eignet sich GPT besonders für Anwendungen wie Textgenerierung, Dialogsysteme und kreative Sprachverarbeitung, bei denen schrittweise eine kohärente und flüssige Ausgabe erzeugt werden muss.
Die anderen im Schaubild verwendeten Begriffe werden in Kürze im Abschnitt “Decoder” näher erläutert.
Die menschliche Sprache besteht aus Hunderttausenden von Wörtern, die sich zudem durch Bedeutungsvarianten, Synonyme und Dialekte unterscheiden. Für Computer ist es eine Herausforderung, mit dieser Vielfalt umzugehen - ähnlich wie für einen Lehrling in einer Werkstatt. Dieser muss nicht nur die Namen der Werkzeuge kennen, sondern auch wissen, dass „Schraubenschlüssel“ und „Gabelschlüssel“ btw. Maulschlüssel dasselbe bedeuten können, während „Bohrer“ und „Fräser“ zwar ähnlich klingen - aber unterschiedliche Werkzeuge sind.
Um Sprache richtig zu verstehen, müssen Computer auch erkennen, wie Begriffe hierarchisch miteinander verknüpft sind. So ist ein Dackel nicht nur ein eigenständiger Begriff, sondern auch eine Gattung von Hunden, die wiederum zu den Säugetieren gehören. Ein Supermarkt funktioniert ähnlich: Obst, Gemüse und Getränke sind in Kategorien organisiert. Ein Kassensystem muss also erkennen, dass eine Orange und eine Banane beide unter die Kategorie „Obst“ fallen, obwohl es sich um offenkundig unterschiedliche Produkte handelt.

Ein weiterer Stolperstein ist die Frage, wie spezifisch oder allgemein Wörter sind. Während „Schraubenzieher“ sehr spezifisch ist, deckt „Werkzeug“ einen sehr weiten Bereich ab. Sprachmodelle müssen daher auch lernen, den richtigen Grad an Allgemeinheit einzuschätzen - vergleichbar mit einem Schreiner, der für ein Möbelstück entweder allgemein „Holz“, spezifisch „Hartholz“ oder ganz speziell „Eiche“ verwenden kann.
Darüber hinaus sind viele Begriffe mehrdeutig und ihre genaue Bedeutung ergibt sich erst aus dem Kontext. So bedeutet das Wort „umfahren“ je nach Betonung entweder ein Hindernis überfahren oder es mehr oder weniger geschickt umgehen. Für einen Elektriker wiederum ist Kabel nicht gleich Kabel: Erst der Kontext, etwa Schaltpläne oder die Umgebung, macht klar, ob es für Strom oder Datenübertragung gedacht ist - Fehler sind hier nicht empfohlen.
Nicht nur die Wörter selbst, sondern auch die Betonung und die Beziehung im Satz bestimmen die Bedeutung des Satzes. So ändert sich die Aussage „Ich habe den Schrank nicht zerlegt“ je nachdem, ob der Schrank betont wird (weil vielleicht der Tisch zerlegt wurde) oder ob das Wort „nicht“ betont wird (weil der Schrank stehen geblieben ist). Auch bei einem Rezept wie „Fisch mit Kräutern bestreuen und 20 Minuten in den Ofen geben“ muss klar sein, dass der Fisch gemeint ist und nicht (nur) die Kräuter.
Um diese Komplexität bewältigen zu können, benötigen Computer Methoden, um Wörter nicht nur als Zeichenketten, sondern tatsächlich mit ihrer Bedeutung zu speichern. Ein Maler gruppiert ähnliche Farbtöne auf seiner Farbpalette nebeneinander; ebenso sollten Wörter wie „Auto“ und „Fahrzeug“, die ähnliche Bedeutungen haben, nahe beieinander stehen, um ihren semantischen Zusammenhang leichter erkennen zu können.
Im Gegensatz zu Datenbanken speichert das menschliche Gehirn Wissen assoziativ, d.h. nicht in Form von strukturierten Listen, sondern in Form von Zusammenhängen und Erinnerungen. Ein Tischler weiss beispielsweise, dass Eiche schwerer als Buche zu bearbeiten ist, ohne notwendigerweise die genaue Dichte auswendig zu kennen. Ähnlich speichern Sprachmodelle allgemeines Wissen und stellen Zusammenhänge her, ohne sich jedes Detail genau zu merken.
Neben dem reinen Verstehen müssen Computer auch in der Lage sein, selbst sinnvolle und grammatikalisch korrekte Texte zu produzieren. Dies ist vergleichbar mit einem Lehrling im ersten Lehrjahr, der zwar Werkzeuge und Materialien identifizieren kann, aber erst später nach praktischer Erfahrung in der Lage ist, ein stabiles und ästhetisch ansprechendes Möbelstück herzustellen.
Ebenso schwierig ist es, Ironie oder Emphase zu erkennen. Menschen sagen oft das Gegenteil von dem, was sie wirklich meinen, oder verwenden subtile Betonungen. „Ja, genau das habe ich mir gewünscht...“ kann entweder ehrliche Begeisterung oder ärgerliche Ironie ausdrücken. Ebenso kann ein Gesichtsausdruck wie ein Lächeln ohne zusätzlichen Kontext leicht als Grimasse missverstanden werden.
Außerdem sprechen Menschen nicht perfekt - sie machen Tippfehler, verwenden Umgangssprache oder lassen Wörter aus. Ein gutes Sprachmodell muss trotzdem verstehen, was gemeint ist, und Fehler korrigieren können. Vergleichbar mit einem Mechaniker, der erkennt, dass eine Schraube schief sitzt und sie deshalb gerade dreht - auch wenn das nicht zu seinem ursprünglichen Plan gehörte.
Schließlich ist Sprache häufig mit visuellen oder anderen Sinnesdaten verknüpft. Moderne KI-Modelle müssen daher lernen, Sprache auch mit Bildern und ähnlichen Informationen zu verknüpfen. So muss eine Bildbeschreibung das abgebildete Objekt korrekt erkennen und gleichzeitig sprachlich sinnvoll formulieren. Ähnlich beschreibt ein Architekt sein Bauprojekt nicht nur mit Worten, sondern veranschaulicht es zusätzlich mit Plänen und Modellen.
Die semantische Suche ist eine Methode der Informationssuche, die nicht nur nach exakten Schlüsselwörtern sucht, sondern die Bedeutung (Semantik) einer Anfrage versteht und aufgrund des inhaltlichen Zusammenhangs passende Inhalte findet. Im Gegensatz zur klassischen Schlagwortsuche, die nur nach exakten Wortübereinstimmungen oder klaren Regeln sucht, kann die semantische Suche auch Synonyme, Kontextzusammenhänge und thematisch verwandte Inhalte berücksichtigen. Dies ermöglicht eine intelligentere und präzisere Suche, insbesondere bei komplexen oder natürlich formulierten Anfragen.
Der Encoder eines Large Language Models (LLM) spielt bei der semantischen Suche eine entscheidende Rolle, da er Texte in eine numerische Repräsentation (Embedding) umwandelt. Dabei analysiert er nicht nur einzelne Wörter, sondern erkennt deren Bedeutung im Kontext.
Ein Embedding stellt Wörter als Vektoren in einem hochdimensionalen Raum dar und ermöglicht es, semantische Beziehungen anhand der Abstände zwischen diesen Vektoren zu messen. Um sich dies besser vorstellen zu können, kann man den dreidimensionalen Raum als Analogie verwenden, in dem zwei Flugzeuge durch ihre Position zueinander beschrieben werden. Wenn zwei Flugzeuge ähnliche Koordinaten auf den Achsen Höhe, Geschwindigkeit und geographische Lage haben, befinden sie sich nahe beieinander. Ähnlich verhält es sich in der Sprache: Wörter mit ähnlicher Bedeutung oder Verwendung liegen im mehrdimensionalen Vektorraum ebenfalls nahe beieinander.
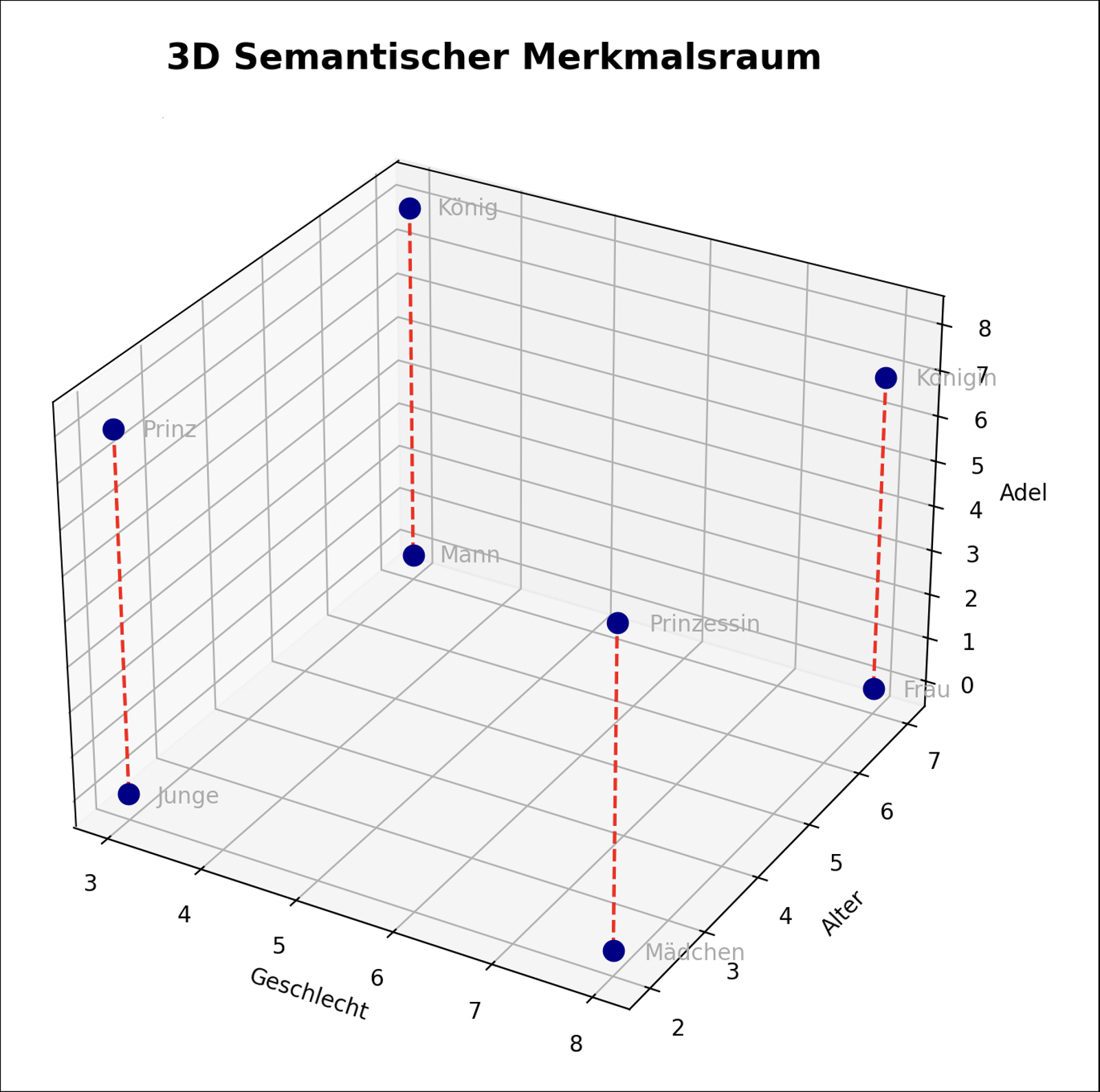
Ein konkretes Beispiel für die semantische Struktur eines solchen hochdimensionalen Raumes sind die Begriffe Werkzeug, Hammer, Nagel, Handwerksmeister und Lehrling. Während die ersten drei Begriffe physische Objekte beschreiben, stehen die letzten beiden Begriffe für Personen. Diese Unterscheidung spiegelt sich im Vektorraum wider: Werkzeuge wie Hammer und Nagel liegen näher beieinander, da sie in Texten häufig zusammen vorkommen und in einer funktionalen Beziehung zueinander stehen - ein Hammer wird zum Einschlagen von Nägeln verwendet. Das allgemeine Wort Werkzeug hingegen liegt ebenfalls in der Nähe, aber etwas weiter entfernt, da es eine Oberkategorie darstellt, die viele verschiedene Werkzeuge umfasst.

Anders verhält es sich mit den Begriffen Handwerksmeister und Auszubildender, die zwar auch zum Bereich des Handwerks gehören, sich aber semantisch von den Gegenständen unterscheiden. Da sie Personen bezeichnen, haben ihre Embeddings ein höheres Gewicht in Dimensionen, die für menschliche Rollen und Beziehungen stehen. Der Handwerksmeister kann einen hohen Wert auf einer Dimension haben, die Autorität oder Erfahrung repräsentiert, während der Lehrling auf derselben Dimension einen niedrigeren Wert hat, da er sich in einer Lernposition befindet. Auf einer anderen Dimension, die das Handwerk als Themenbereich repräsentiert, haben beide Begriffe jedoch ähnliche Werte, was darauf hindeutet, dass sie inhaltlich verwandt sind.
Diese hochdimensionalen Beziehungen helfen Sprachmodellen, nicht nur Wortbedeutungen, sondern auch deren Funktion und Kontext zu verstehen. So erkennt ein Modell beispielsweise, dass ein Satz über einen Handwerksmeister, der einem Lehrling zeigt, wie man mit einem Hammer einen Nagel einschlägt, eine logische und inhaltlich kohärente Aussage ist. Die enge Beziehung zwischen Hammer und Nagel wird durch ihre Nähe im Vektorraum repräsentiert, während die Unterscheidung zwischen Werkzeug und Mensch durch unterschiedliche Dimensionen widergespiegelt wird. Auf diese Weise kann ein Sprachmodell nicht nur ähnliche Begriffe gruppieren, sondern auch ihre kontextuelle Beziehung richtig einordnen.

Der Encoder eines LLM hat die Aufgabe, die Eingabedaten in technisch verarbeitbare Embeddings umzuwandeln, indem er sie schrittweise analysiert und in eine kompakte, bedeutungshaltige Repräsentation überführt. Dieser Prozess ähnelt der Arbeit eines professionellen Archivars, der ein neues Dokument in ein geordnetes System einfügt. Zunächst muss der Text zerlegt (Tokenisierung) und analysiert werden - vergleichbar mit der Archivierung eines neuen Buches, das zunächst nach Titel, Thema und Inhalt geordnet wird. In der ersten Phase verarbeitet der Encoder die Token, also die einzelnen Wörter oder Wortbestandteile, und wandelt sie mit Hilfe von Einbettungsvektoren in eine numerische Darstellung um. Dies entspricht einer Bibliotheksklassifikation, bei der jedes Buch eine spezifische Kategorisierung erhält, um es später leicht auffindbar zu machen.
Im nächsten Schritt nutzt der Encoder den Mechanismus der Self-Attention, um zu erkennen, welche Wörter im gegebenen Kontext besonders wichtig sind. Dies funktioniert wie bei einem Archivar, der nicht nur den Titel eines Buches betrachtet, sondern auch prüft, welche anderen Bücher thematisch verwandt sind, ob es Querverweise zu anderen Werken gibt oder ob ein Begriff in verschiedenen Kapiteln unterschiedlich verwendet wird. So kann der Encoder beispielsweise erkennen, dass das Wort "Nagel" in dem Satz "Der Handwerker schlägt einen Nagel in die Wand" eine andere Bedeutung hat als in "Sein Nagel ist abgebrochen", weil es in unterschiedlichen thematischen Zusammenhängen steht.
Analogie: Archivar in einem Archivsystem
Anschließend werden diese Informationen durch mehrere Schichten eines neuronalen Netzes, vergleichbar mit den verschiedenen Abteilungen eines Archivs, verarbeitet, in denen die Dokumente nach Relevanz, Detaillierungsgrad und inhaltlichen Zusammenhängen weiter kategorisiert werden. Am Ende dieses Prozesses gibt der Encoder nicht mehr die ursprünglichen Wörter aus, sondern eine Reihe von hochdimensionalen Vektoren, die die Bedeutung und den Kontext der Eingabe repräsentieren. Diese Embeddings sind nun bereit für den Decoder, der daraus eine kohärente und sinnvolle Ausgabe generieren kann - ähnlich einem Archivsystem, das auf Anfrage alle relevanten Dokumente zu einem bestimmten Thema liefert.
Bei Large Language Models (LLMs) beschreibt ein Kontextfenster die maximale Textmenge, die das Modell gleichzeitig verarbeiten und dabei berücksichtigen kann. Man könnte sagen, es ist das Gedächtnis des Modells für die aktuelle Kommunikation oder Aufgabe. Man kann es mit dem Arbeitstisch eines Handwerkers vergleichen: Je größer dieser Tisch ist, desto mehr Werkzeuge und Materialien passen gleichzeitig darauf und desto leichter kann der Handwerker arbeiten, ohne ständig suchen oder umräumen zu müssen. Je größer das Kontextfenster eines LLMs ist, desto besser kann das Modell lange Texte, ganze Dokumente oder ausführliche Gespräche verarbeiten, ohne wichtige Details zu vergessen. Ist das Kontextfenster hingegen zu klein, „vergisst“ das Modell Informationen vom Anfang des Textes, ähnlich wie ein Handwerker, der ständig heruntergefallene Werkzeuge von seinem kleinen Tisch aufheben und neu sortieren muss. Ein großes Kontextfenster verbessert also nicht nur die Qualität der Antworten, sondern ermöglicht auch völlig neue Anwendungsfälle wie die Bearbeitung ganzer Bücher oder die umfassende Analyse großer Softwareprojekte.
Wichtig ist außer der reinen Textbedeutung auch die Formulierung des Eingabetexts für den Enkoder. Prompt Engineering bezeichnet dabei die gezielte Formulierung von Eingaben (Prompts), um optimale Antworten von KI-Modellen zu erhalten. Gute Prompts enthalten klare Anweisungen, spezifischen Kontext und gegebenenfalls Beispiele. Ähnlich einem Regisseur, der klare Anweisungen gibt, kann der Nutzer so sicherstellen, dass das Modell präzise Ergebnisse liefert. Da GPT-Modelle ausschließlich auf Grundlage des eingegebenen Kontexts Antworten generieren, hat die Gestaltung des Prompts maßgeblichen Einfluss auf die Qualität und Genauigkeit der generierten Texte. Weiterführende Informationen und viele Beispiele finden sich z.B. in den Artikeln von Datacamp und 121watt.
Dies führt uns zu der Frage, wie ein LLM aus der Eingabe in Form von Embeddings eine Antwort generiert und warum dies typischerweise Wort für Wort geschieht.
Die Decoder-Architektur eines Transformers basiert auf tiefen neuronalen Netzen (Deep Learning), die in mehreren Verarbeitungsschritten trainierte Gewichte zur Textgenerierung verwenden. Ein neuronales Netz ist eine computergestützte Modellstruktur, die aus mehreren Schichten künstlicher Neuronen besteht. Diese Neuronen verarbeiten Eingaben, gewichten sie und leiten sie weiter, um komplexe Zusammenhänge zu erkennen. Deep Learning bezeichnet eine spezielle Form des maschinellen Lernens, bei der solche neuronalen Netze besonders viele Schichten (daher „tief“) haben und mit großen Datenmengen und optimierten Algorithmen trainiert werden.
Im Decoder des Transformers kommen mehrere dieser tiefen neuronalen Netze zum Einsatz: Das Multi-Head-Attention-Netz verwendet vollständig verbundene neuronale Netze, um zu berechnen, welche Teile eines Textes für die aktuelle Wortgenerierung wichtig sind. Multi-Head Attention ist dabei eine Erweiterung von Self-Attention, bei der mehrere unabhängige Self-Attention-Berechnungen (Heads) parallel durchgeführt werden. Man kann sich dieses als den Einsatz mehrerer Experten, die einen Text aus unterschiedlichen Perspektiven analysieren, vorstellen. Jeder Head lernt unterschiedliche Beziehungen zwischen den Wörtern, was die Repräsentation verbessert. Das Feed-Forward-Network besteht aus mehreren hintereinander geschalteten neuronalen Schichten mit nichtlinearer Aktivierung und hilft, komplexe Zusammenhänge und Muster zu erfassen. Die Softmax-Funktion in der Ausgabeschicht wandelt schließlich die berechneten Werte in Wahrscheinlichkeiten für das nächste Wort um. Durch diese mehrschichtige neuronale Struktur ermöglicht Deep Learning dem Decoder, kontextbezogene, grammatikalisch korrekte und sinnvolle Texte zu generieren, indem das Modell aus großen Mengen von Trainingsdaten lernt.
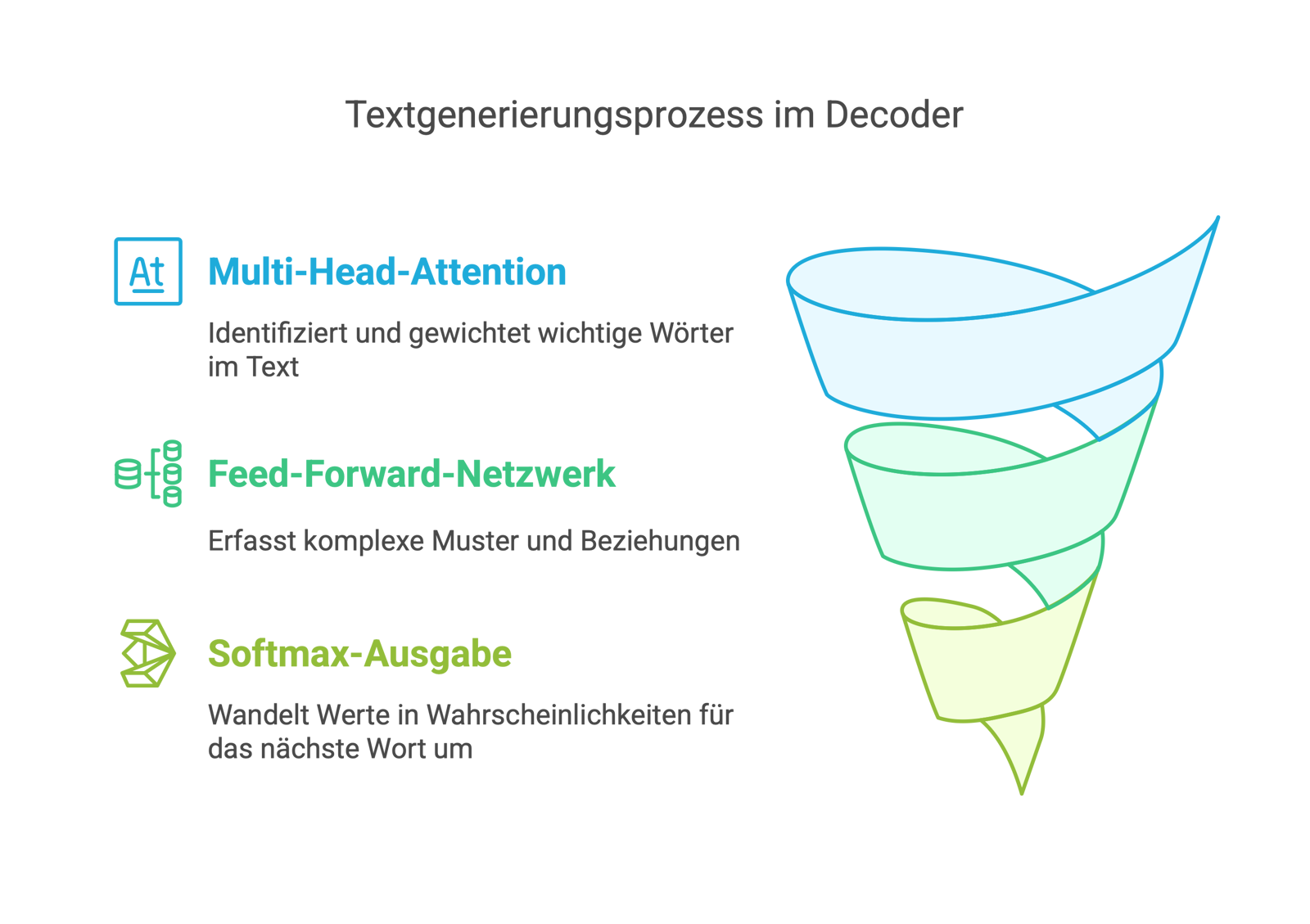
Ein Decoder kann auch in Analogie zu einem professionellen Übersetzer erklärt werden, der einen Text Stück für Stück übersetzt und dabei mehrere kognitive Prozesse gleichzeitig einsetzt. Die Multi-Head Attention entspricht der Fähigkeit des Übersetzers, sich gleichzeitig auf verschiedene Aspekte des Ausgangstextes zu konzentrieren: Er berücksichtigt die gesamte bisher übersetzte Passage, überprüft die ursprüngliche Bedeutung und achtet auf grammatikalische Strukturen, um eine präzise Übersetzung zu liefern. Das Feed-Forward-Netzwerk ist vergleichbar mit dem inneren Sprachgefühl des Übersetzers, das ihm hilft, die gewählten Formulierungen weiter zu verfeinern, Synonyme zu erkennen und den Satzbau an die Zielsprache anzupassen. Schließlich übernimmt die Softmax-Funktion die Rolle der endgültigen Wortwahl: Der Übersetzer kann mehrere passende Begriffe im Kopf haben, bewertet die Wahrscheinlichkeit ihrer Eignung im jeweiligen Kontext und entscheidet sich dann für das treffendste Wort. Auf diese Weise stellt der Decoder sicher, dass die generierte Ausgabe sowohl inhaltlich korrekt als auch sprachlich flüssig ist.
Um eine passende Antwort auf die vom Encoder übermittelte Anfrage generieren zu können, greift der Decoder auf bereits trainierte neuronale Netze zurück. Dabei kommen verschiedene Trainingsmethoden zum Einsatz. Vorher allerdings noch einige Informationen, wie das Wissen in den neuronalen Netzen des Decoders gespeichert wird.
Ein wesentliches Element, das es dem Decoder ermöglicht, auf erlerntes Wissen zurückzugreifen, sind die Millionen von Parametern in den neuronalen Netzen des Decoders, die während des Trainingsprozesses optimiert werden. Diese Parameter stellen die Gewichte dar, die innerhalb des neuronalen Netzwerks bestimmen, wie stark ein bestimmtes Eingabewort mit anderen Konzepten oder Mustern in Verbindung steht. Man kann sich diese Gewichte als eine Art Gedächtnis des Modells vorstellen, das es ihm erlaubt, auf bereits erlernte sprachliche Strukturen und Bedeutungen zurückzugreifen.
Um diese Idee verständlicher zu machen, kann man sich das neuronale Netzwerk eines Sprachmodells wie ein großes Netz von künstlichen Neuronen in mehreren Ebenen (Schichten) vorstellen, das ähnlich wie das menschliche Gehirn durch Training Verbindungen zwischen Konzepten herstellt. Jedes dieser künstlichen Neuronen ist mit anderen verbunden, und die Gewichte bestimmen die Stärke dieser Verbindungen. Wenn ein GPT-Modell beispielsweise das Wort „Arzt“ verarbeitet, werden durch die Gewichtungen automatisch verwandte Begriffe wie „Patient“, „Krankenhaus“ oder „Diagnose“ mit einer höheren Relevanz aktiviert. Diese semantischen Assoziationen sind das Ergebnis eines umfangreichen Trainingsprozesses, bei dem das Modell auf riesigen Mengen an Textdaten gelernt hat, welche Wörter häufig in ähnlichen Kontexten auftreten.
Die Anzahl der benötigten Parameter wächst dabei exponentiell mit der Komplexität des Modells. Moderne Large Language Models wie GPT-4 verfügen über Hunderte von Milliarden solcher Parameter, die durch aufwendige Rechenoperationen feinjustiert werden. Jeder dieser Parameter trägt dazu bei, sprachliche Nuancen, grammatikalische Strukturen und stilistische Feinheiten zu erfassen. Man kann sich das Modell als eine gigantische, dynamische Mustererkennungsmaschine vorstellen, die basierend auf ihren gewichteten Verbindungen neue Texte generiert, indem sie die wahrscheinlichsten nächsten Wörter voraussagt.
Während des Trainingsprozesses werden diese Parameter kontinuierlich angepasst, um die Qualität der Vorhersagen zu verbessern. Ohne diese große Anzahl an optimierten Parametern wäre das Modell nicht in der Lage, kohärente, kontextbezogene und stilistisch angemessene Antworten zu erzeugen. Die enorme Rechenleistung, die für die Anpassung dieser Parameter erforderlich ist, zeigt, warum das Training moderner Sprachmodelle ein so ressourcenintensiver Prozess ist und warum das Pretraining eine so entscheidende Rolle für die spätere Leistungsfähigkeit des Decoders spielt.
Das Pretraining spielt eine zentrale Rolle für die neuronalen Netze des Decoders, da es die Grundlage für ihre Fähigkeit zur Verarbeitung natürlicher Sprache legt. Während des Pretrainings wird das Modell mit großen Mengen von Textdaten trainiert, um statistische Muster, grammatikalische Strukturen und semantische Zusammenhänge zu erlernen. Dabei werden die Gewichte von Multi-Head Attention, Feed-Forward-Network und Softmax-Schicht so optimiert, dass das Modell lernt, relevante Wörter miteinander in Beziehung zu setzen, sinnvolle Satzstrukturen zu erkennen und realistische Wahrscheinlichkeiten für die nächste Wortwahl zu berechnen. Ohne dieses Pretraining wäre der Decoder nicht in der Lage, kohärente und sinnvolle Texte zu generieren, da er keine sprachlichen Muster aus der Vergangenheit kennt. Das Pretraining wird häufig an großen Textkorpora durchgeführt, bevor das Modell durch Feintuning auf spezifische Aufgaben wie maschinelle Übersetzung oder Frage-Antwort-Systeme spezialisiert wird.
Ein zentraler Mechanismus, mit dem ein LLM während des Pretrainings lernt, ist die Backpropagation, ein Verfahren zur Anpassung der Gewichte innerhalb des neuronalen Netzwerks. Dieser Prozess kann anhand eines einfachen Beispiels erläutert werden: Angenommen, das Modell soll lernen, den Satz „Der Himmel ist …“ korrekt fortzusetzen. Während des Trainings gibt man dem Modell eine große Anzahl von Beispielsätzen vor, und in diesem Fall wäre das korrekte nächste Wort „blau“. Das Modell generiert jedoch zunächst eine Vorhersage basierend auf seinen aktuellen Gewichtungen und könnte beispielsweise „weit“ oder „schön“ als wahrscheinlichste Wörter vorschlagen. Da jedoch „blau“ die wahrscheinlichere Fortsetzung ist, wird der Fehler (die Differenz zwischen der Vorhersage des Modells und der richtigen Antwort) berechnet. Dieser Fehler wird dann durch das gesamte neuronale Netzwerk rückwärts propagiert (Backpropagation), um die Gewichte in den vorhergehenden Schichten so anzupassen, dass in zukünftigen Vorhersagen „blau“ eine höhere Wahrscheinlichkeit erhält. Dies geschieht durch die Berechnung der Gradienten – also der Richtung und Stärke, in die die Gewichte verändert werden müssen – und die anschließende Optimierung mit einem Algorithmus wie Stochastic Gradient Descent (SGD) oder Adam-Optimizer. Nach vielen Iterationen dieses Prozesses kann das Modell schließlich lernen, dass „Der Himmel ist blau“ eine der wahrscheinlichsten Fortsetzungen ist und dies in zukünftigen Generierungen korrekt vorhersagen. Dieses kontinuierliche Anpassen der Gewichte durch Backpropagation ist das Fundament des Lernprozesses in tiefen neuronalen Netzwerken und ermöglicht es, dass das Modell mit jeder Trainingsphase präzisere und kontextgerechtere Antworten liefert.
Transferlernen ist ein allgemeiner Begriff, der beschreibt, wie ein bereits vortrainiertes Modell für eine neue, oft spezialisierte Aufgabe angepasst wird. Dabei werden die während des Pretrainings erlernten Sprachstrukturen und Muster genutzt, um das Modell mit vergleichsweise wenigen zusätzlichen Daten auf eine neue Domäne oder Anwendung zu übertragen. Ein Beispiel wäre die Feinabstimmung eines generellen Sprachmodells auf juristische Texte, um es für Rechtsdokumente nutzbarer zu machen. Transferlernen kann z.B. durch Posttraining erfolgen. Transferlernen ist dabei als Begriff allgemeiner gefasst als Posttraining, da hier auch weitere spezielle Lernformen wie Finetuning, Feature-Based Transfer Learning, Adapters und LoRA (Low-Rank Adaptation) etc. verwendet werden können.
Posttraining ist eine Form der Weiterentwicklung eines bereits vortrainierten Sprachmodells, nachdem es zunächst auf allgemeinen Textdaten gelernt hat. Während ein Modell beim Pretraining allgemeine Sprachmuster, Grammatik und Kontextbeziehungen aus großen Textmengen lernt, werden beim Posttraining zusätzliche, spezialisierte Daten verwendet, um das Modell für bestimmte Anwendungsfälle zu optimieren. Diese Anpassung ist vergleichbar mit einem Koch, der nach seiner Ausbildung zwar kochen kann, sich aber später auf eine bestimmte Küche spezialisiert. Beim Post-Training werden häufig branchenspezifische Texte, Dokumentationen oder firmeneigene Daten verwendet, um das Modell auf bestimmte Fachgebiete wie Medizin, Recht oder Technik zuzuschneiden. Das Ergebnis ist ein Sprachmodell, das deutlich besser an die individuellen Bedürfnisse angepasst ist und damit präziser, relevanter und überzeugender antwortet.
Reinforcement Learning with Human Feedback (RLHF) ist als spezielle Form des Posttrainings eine wichtige Ergänzung zum Pretraining eines Large Language Models (LLM), da es dem Modell hilft, nicht nur sprachliche Muster zu erlernen, sondern auch auf menschenähnliche Weise nützliche, sichere und erwünschte Antworten zu geben. Während das Pretraining das Modell auf einer großen Menge von Textdaten trainiert und es ihm ermöglicht, Sprache zu verstehen und zu generieren, fehlen oft explizite Anreize für die Qualität und Angemessenheit der Antworten. Hier setzt RLHF an: Durch menschliches Feedback lernt das Modell, welche Antworten bevorzugt werden sollten. Dies geschieht in einem Reinforcement-Learning-Prozess, bei dem das Modell verschiedene Antwortmöglichkeiten generiert, die dann von menschlichen Annotatoren bewertet werden. Diese Bewertungen dienen als Grundlage für ein Belohnungsmodell, das das LLM so optimiert, dass bevorzugte Antworten häufiger erzeugt werden. Ein Beispiel wäre die Verbesserung der Höflichkeit, Relevanz oder Verständlichkeit von Antworten, die in einem reinen Pretraining nicht ausreichend berücksichtigt wurden.
Der Unterschied zwischen Posttraining und RLHF liegt in der Methode der Anpassung. Posttraining ist ein eher klassisches Feintuning nach dem Pretraining, bei dem das Modell mit zusätzlichen spezifischen Daten trainiert wird - beispielsweise mit medizinischen Fachtexten für ein spezialisiertes Modell. Diese Methode passt die Gewichte des neuronalen Netzes durch weiteres überwachtes Lernen an. RLHF hingegen nutzt menschliche Präferenzbewertungen in einem iterativen Lernprozess, so dass das Modell durch ein zusätzliches Belohnungssystem kontinuierlich verbessert wird. Während das Post-Training also eher eine einmalige Erweiterung der Wissensbasis oder eine Anpassung an eine bestimmte Domäne ist, stellt RLHF eine dynamische Optimierung der Outputqualität dar, die das Modell menschenähnlicher und nützlicher macht.
Ein zentrales Phänomen bei der Verwendung von LLMs ist, dass sie manchmal falsche Tatsachen erfinden, sogenannte „Halluzinationen“. Dies hängt unmittelbar mit ihrer Funktionsweise zusammen: LLMs erzeugen Texte nicht auf der Basis eines geprüften Wissensspeichers, sondern - wie beschrieben - durch die Berechnung von Wahrscheinlichkeitsverteilungen für das jeweils nächste Wort. Das Modell wählt in jedem Schritt das statistisch wahrscheinlichste Token auf Basis der vorherigen Tokens aus - ohne notwendigerweise zu prüfen, ob der Inhalt inhaltlich korrekt ist. Diese fehlende Verankerung in einer externen Faktenbasis (fehlendes Grounding) führt dazu, dass LLMs zwar sprachlich überzeugende, aber inhaltlich falsche Aussagen machen können. Beispielsweise kann ein Modell auf eine Frage aus Geschichte, Medizin oder Technik eine plausible Antwort formulieren, die jedoch nicht auf einer verlässlichen Quelle beruht, sondern lediglich aus Mustern der Trainingsdaten rekonstruiert wurde. Insbesondere bei offenen Fragen ohne klaren Bezug oder bei widersprüchlichen Sprachmustern neigen Modelle dazu, Inhalte zu „erfinden“, um Lücken zu füllen. Um diesem Problem zu begegnen, werden zunehmend Ansätze wie Retrieval-Augmented Generation (RAG) eingesetzt, bei denen das Modell während der Antwortgenerierung gezielt auf externe, verifizierte Wissensquellen zugreifen kann.
Bisher wurde meist Bezug auf OpenAI und ChatGPT genommen, es gibt jedoch mittlerweile eine Vielzahl von Unternehmen und Projekten, die generative Sprachmodelle (GPTs) bzw. Large Language Models (LLMs) anbieten und kontinuierlich weiterentwickeln. Zu den führenden kommerziellen Anbietern zählen wie erwähnt OpenAI mit ChatGPT, Microsoft im Rahmen des Azure-Ökosystems, Anthropic mit Claude, Google mit Gemini, xAI mit Grok sowie weitere Unternehmen wie Cohere und AI21 Labs. Diese Anbieter verfolgen in der Regel einen kommerziellen Ansatz, bei dem die Modelle über Cloud-Plattformen bereitgestellt und gegen Nutzungsentgelte verfügbar gemacht werden. Im Folgenden erhältst du einen Überblick über einige der bekanntesten Anbieter sowie einen abschließenden Abschnitt über Open-Source-LLMs und deren Vorteile.
OpenAI gilt als Pionier im Bereich generativer KI-Modelle und hat mit GPT-3, GPT-3.5, GPT-4(o) und den jüngsten Modellen GPT-4.5 und GPT-o3 (pro) die Verbreitung neuronaler Sprachmodelle maßgeblich vorangetrieben. ChatGPT, basierend auf den GPT-Modellen, ist ein Gesprächsmodell, das für interaktive Dialoge optimiert ist und durch seine hohe Textqualität große Bekanntheit erlangt hat. OpenAI hat kürzlich auch ChatGPT Plus und ChatGPT Enterprise eingeführt, um den Bedürfnissen von Privatnutzern und Unternehmen gerecht zu werden.
Microsoft arbeitet eng mit OpenAI zusammen und integriert deren Modelle in die eigene Azure-Cloud Plattform. Dadurch erhalten Unternehmen direkten Zugriff mit genau definierten Service Level Agreements auf die neuesten GPT-Technologien, wie GPT-4o, und können diese nahtlos in ihre bestehende Cloud-Infrastruktur einbinden. Zusätzlich hat Microsoft Copilot entwickelt, einen KI-Assistenten, der in Produkten wie Microsoft 365, GitHub, Edge und in Entwicklerwerkzeugen integriert ist und derzeit auf den Modellen von OpenAI basiert.
Anthropic, ein relativ junges KI-Forschungsunternehmen, bietet mit Claude ein leistungsfähiges Chat- und Sprachmodell an. Das neueste Modell, Claude 4.0 Opus / Sonnet, gilt als besonders fortschrittlich in Bezug auf Textverständnis und Konversationsfähigkeit und konkurriert direkt mit den Modellen von OpenAI und Microsoft.
Google hat seine Bemühungen im Bereich der KI-Sprachmodelle mit Gemini gebündelt, einem multimodalen Modell, das die Nachfolge von PaLM und dem Konversationssystem Bard antritt. Gemini ist in verschiedene Google-Produkte integriert und deckt ein breites Spektrum an Anwendungen ab, von der Suche bis hin zu kreativen Aufgaben.
Das von Elon Musk gegründete Unternehmen xAI hat mit Grok ein leistungsfähiges Large Language Model (LLM) entwickelt, das sich ebenfalls durch seine Fähigkeit auszeichnet, natürliche und menschenähnliche Gespräche zu führen. Grok ist darauf ausgelegt, komplexe Fragen präzise zu beantworten und liefert oft humorvolle und kreative Antworten. Ein herausragendes Merkmal von Grok ist sein exklusiver Zugang zu den Daten von X (ehemals Twitter). Diese einzigartige Datenquelle ermöglicht es dem Modell, Echtzeitinformationen und aktuelle Trends direkt von einer der größten sozialen Plattformen zu integrieren. Dadurch hat Grok einen klaren Vorteil bei der Verarbeitung von tagesaktuellen Ereignissen und Meinungen, was es hier von anderen Modellen unterscheidet.
DeepSeek ist ein aufstrebendes Unternehmen im Bereich der generativen KI aus China und hat mit DeepSeek R1 ein spezialisiertes Large Language Model entwickelt, das sich auf wissenschaftliche Forschung, Datenanalyse und technische Dokumentation konzentriert. DeepSeek R1 zeichnet sich wie andere Modelle durch seine Fähigkeit aus, hochpräzise und kontextsensitive Antworten in anspruchsvollen Fachgebieten zu liefern. Besonders bemerkenswert ist jedoch, dass es DeepSeek gelungen ist, ein hochmodernes Modell mit vergleichsweise geringen Ressourcen zu entwickeln und zu trainieren. Erreicht wurde dies durch innovative Ansätze des maschinellen Lernens und der Modelloptimierung, die eine effizientere Nutzung von Rechenleistung und Daten ermöglichen. DeepSeek R1 wird sowohl als Cloud-Service als auch in einer Open-Source-Variante angeboten, was eine flexible Nutzung und Anpassung ermöglicht.
Alibaba's Qwen ist eine Familie generativer KI-Modelle mit multimodalen Fähigkeiten, die Text, Bilder und Audio verarbeiten können. Modelle wie Qwen-7B, Qwen-VL und Qwen2.5-VL sind Open-Source und für Entwickler sowie Unternehmen zugänglich, wobei Letztere mit über 100 Millionen Nutzern Einschränkungen haben. Qwen2.5-VLanalysiert Texte und Bilder, versteht visuelle Inhalte und kann Geräte steuern. Alibaba zufolge übertrifft Qwen2.5-Max Modelle wie DeepSeek-V3 und ChatGPT in Mathematik und Programmierung. Der Open-Source-Ansatz fördert die Weiterentwicklung durch Entwickler und stärkt damit Alibaba’s Position im chinesischen und globalen KI-Wettbewerb.
Cohere konzentriert sich auf Sprachmodelle für den Unternehmenseinsatz und bietet spezialisierte Modelle für Aufgaben wie Textgenerierung, Klassifizierung und semantische Suche an. Ihr neuestes Modell, Command-R, ist darauf ausgelegt, komplexe Anfragen zu bearbeiten und in Unternehmensworkflows integriert zu werden.
AI21 Labs hat mit Jurassic-2 und nachfolgenden Modellen eigene LLMs entwickelt, die flexible Preismodelle und Integrationsmöglichkeiten für umfangreiche Textverarbeitungsprojekte bieten. Ihr Fokus liegt auf der Bereitstellung von Modellen, die für spezifische Branchenanforderungen angepasst werden können.
Neben diesen kommerziellen Anbietern hat sich in den letzten Jahren ein starkes Open-Source-Ökosystem für große Sprachmodelle etabliert. Projekte wie GPT-Neo, GPT-NeoX und BLOOM wurden von Forschungseinrichtungen, Non-Profit-Organisationen und Entwickler-Communities ins Leben gerufen und bieten frei verfügbare Modelle mit unterschiedlichen Größen und Fähigkeiten. Meta hat mit LLaMA 3 einen bedeutenden Beitrag geleistet, indem sie das Modell der Forschungsgemeinschaft zugänglich gemacht haben. Weitere bemerkenswerte Open-Source-Projekte sind Mistral und Grok (2), die leistungsstarke Modelle anbieten, welche oft mit kommerziellen Alternativen konkurrieren können. Auch chinesische Anbieter wie Deepseek und Alibaba (Qwen-Modelle) sind hier aktiv.
Der grundlegende Vorteil von Open-Source-LLMs liegt in ihrer hohen Anpassbarkeit. Da der Quellcode und in vielen Fällen auch die Modellgewichte öffentlich zugänglich sind, können Entwickler und Organisationen die Modelle nach Bedarf modifizieren, auf spezifischen Datensätzen nachtrainieren oder lokal installieren. Dies ermöglicht eine vollständige Kontrolle über Daten und Datenschutz, ohne auf Cloud-Dienste angewiesen zu sein. Zudem können Organisationen mit ausreichender Recheninfrastruktur die Modelle von lokaler PC Hardware bis hinzu speziellen AI Servern eigenständig skalieren. Die offene Entwicklung fördert auch den wissenschaftlichen Austausch und erhöht die Transparenz in Bezug auf Training, Architektur und ethische Aspekte der Modelle.
|
Kriterium |
Kommerzielle Modelle |
Open-Source-Modelle |
|---|---|---|
|
Zugang |
Über Cloud-Services, meist kostenpflichtig |
Frei zugänglich, häufig auch lokal ausführbar |
|
Anpassbarkeit |
Eingeschränkt (Blackbox) |
Vollständig anpassbar (Quellcode und Gewichte verfügbar) |
|
Datenschutz |
Datenverarbeitung meist extern (Cloud, auf DSGVO achten) |
Lokale Verarbeitung möglich, volle Datenhoheit |
|
Support & SLA |
Kommerzieller Support, Service Level Agreements verfügbar |
Community-Support, kein garantierter Service |
|
Rechenanforderungen |
Kein eigener Server notwendig, Nutzung über Anbieterplattform |
Eigene Infrastruktur erforderlich (abhängig vom Modell) |
|
Weiterentwicklung |
Zentral durch Unternehmen gesteuert |
Community- oder konsortialgetriebene Weiterentwicklung |
|
Transparenz |
Begrenzte Einblicke in Trainingsdaten und Methoden |
Hohe Transparenz durch offene Veröffentlichungen |
|
Kostenkontrolle |
Laufende Gebühren pro Nutzung (z.B. Tokenkosten) |
Einmalige Kosten (Hardware, Strom), kein Vendor Lock-in |
|
Beispielanbieter |
OpenAI, Microsoft, Google, Anthropic |
Meta (LLaMA), Mistral, BLOOM, GPT-NeoX, DeepSeek, Qwen usw. |
Hier noch einige aktuelle Entwicklungen im Bereich LLM die gerade oder in naher Zukunft eine Rolle spielen und in neuen GPT Versionen verfügbar gemacht werden.
Die Integration von „Chain-of-Thought“ (CoT)-Reasoning wird oft als ein entscheidender Schritt angesehen, um GPT-Modelle intelligenter und verständlicher zu machen. CoT ermöglicht es dem Modell, seine Gedankengänge strukturiert darzustellen, was zu präziseren und fundierteren Antworten führt. Alles deutet darauf hin, dass GPT-5 - dessen Veröffentlichung noch aussteht - diese Technik weiter ausbauen wird. Die o1/o3-Modelle von OpenAI, die ab September 2024 eingeführt wurden, verwenden CoT bereits automatisch.
Auch GPT-4.5, das im Februar 2025 veröffentlicht wurde, bringt verbesserte Reasoning-Fähigkeiten mit sich, obwohl keine spezifischen Details zur Integration von CoT bekannt sind. Dies lässt vermuten, dass zukünftige Modelle diese Technologie weiter optimieren werden, um noch komplexere Aufgaben zu bewältigen und eine bessere Benutzererfahrung zu bieten.
Der Trend zu immer größeren Kontextfenstern hält unvermindert an. Der im November 2023 erscheinende GPT-4 Turbo verarbeitet bereits beeindruckende 128.000 Token - das entspricht etwa 96.000 Wörtern. Damit lassen sich komplette Codebasen analysieren oder umfangreiche Dokumente in einem Durchgang verarbeiten, ohne sie mühsam in kleinere Abschnitte zerlegen zu müssen.
Obwohl OpenAI keine offizielle Zahl zur Kontextfenstergröße von GPT-4.5 veröffentlicht hat, deutet vieles darauf hin, dass es erneut gewachsen ist. Es ist davon auszugehen, dass GPT-5 diesen Weg konsequent weitergehen wird, um eine noch effizientere Verarbeitung großer Datenmengen zu ermöglichen - ein echter Gamechanger für Entwickler, Unternehmen und alle, die mit komplexen Inhalten arbeiten.
Spitzenreiter in dieser Disziplin ist aktuell Googles Gemini 2.5 Modell mit 1 Million Input-Tokens (1.048.576 Tokens). Dies entspricht etwa 1.500 Seiten Text oder 30.000 Zeilen Code.
Ein weiterer wichtiger Fortschritt in der Entwicklung von KI-Systemen ist der Einsatz intelligenter Agenten, die Aufgaben nicht nur verstehen, sondern auch aktiv ausführen können. Während Modelle wie GPT-4o bereits beeindruckende Interaktionen ermöglichen, geht die nächste Generation noch einen Schritt weiter: Zukünftige KI-Agenten sollen in der Lage sein, eigenständig zu recherchieren, Dokumente zu analysieren oder komplexe Workflows zu automatisieren.
Eine zentrale Rolle spielt dabei das Konzept der Retrieval-Augmented Generation (RAG). Statt sich ausschließlich auf das statische Wissen eines Modells zu verlassen, kombiniert RAG KI-generierte Antworten mit dynamisch abgerufenen Informationen aus externen Datenquellen - zum Beispiel aus unternehmenseigenen Wissensdatenbanken, Cloud-Diensten oder internen Dokumentationen. Das bedeutet, dass Unternehmen künftig KI-Agenten einsetzen können, die auf ihre spezifischen Daten zugreifen, ohne dass diese vorher direkt in das Modell eingespeist werden müssen.
In der Praxis könnte ein RAG-basierter Agent beispielsweise eine firmenspezifische Supportanfrage beantworten, indem er interne Handbücher durchsucht, relevante Passagen extrahiert und daraus eine präzise Antwort generiert. Auch in der Softwareentwicklung ergeben sich spannende Anwendungsfälle - etwa die automatische Analyse von Code-Repositories oder das gezielte Auffinden von Fehlern in komplexen Systemen.
Mit der Einführung von OpenAI's "Operator" im Januar 2025 wurde ein großer Schritt in Richtung autonomer KI-Agenten gemacht. „Operator“ basiert auf dem neuen „Computer-Using Agent“ (CUA), einer Variante von GPT-4o, und bringt erweiterte Reasoning-Fähigkeiten mit. In der Praxis bedeutet dies, dass er selbstständig Reisen buchen, Lebensmittel bestellen oder sogar Memes erstellen kann - und zwar direkt über einen Webbrowser.
Derzeit ist Operator" exklusiv für Abonnenten des $200 pro Monat ChatGPT-Pro-Plans verfügbar, aber OpenAI plant, den Zugang in Zukunft zu erweitern. Langfristig könnte diese Technologie in GPT-Modelle integriert werden, um alltägliche Aufgaben effizient zu automatisieren und die Interaktion mit Computern auf eine neue Ebene zu heben.
In diesem Zusammenhang ist ein weiterer zukunftsweisender Ansatz zur Nutzung von LLMs in Unternehmen der Einsatz sogenannter MCP Server (Model Context Protocol). Dabei handelt es sich um eine offene, leichtgewichtige Schnittstelle, mit der sich interne Datenquellen, APIs oder Workflows standardisiert an LLMs anbinden lassen – unabhängig davon, ob das Modell lokal betrieben oder über eine Cloud-Plattform genutzt wird. Der MCP-Server agiert dabei als Vermittler zwischen dem Sprachmodell und den unternehmensspezifischen Ressourcen. So kann ein LLM etwa eine Supportanfrage entgegennehmen, über den MCP-Server relevante Daten aus der internen Wissensdatenbank abfragen oder sogar einen ERP-Workflow starten. Die Anfragen erfolgen dabei über ein einheitliches Protokoll (z. B. STDIO, HTTP, SSE oder OpenAPI), was eine sichere und modular erweiterbare Architektur ermöglicht. Für Unternehmen bedeutet dies: Sie behalten die Kontrolle über ihre Daten, können bestehende Systeme weiterverwenden und gleichzeitig die Vorteile moderner Sprach-KI nutzen – ohne das Modell selbst verändern zu müssen. Die Trennung von Modell und Datenzugriff erhöht zudem die Transparenz und reduziert regulatorische Risiken bei der Nutzung von KI im professionellen Umfeld. Siehe hier auch unser Beitrag zu den Testmöglichkeiten lokaler MCP Server.
Die OpenAI Realtime API ermöglicht Echtzeit-Sprachverarbeitung über eine WebSocket-basierte Schnittstelle, die sowohl Text- als auch Audioeingabe und -ausgabe unterstützt. Die extrem niedrige Latenz ermöglicht eine flüssige und unmittelbare Interaktion mit KI-basierten Anwendungen, was insbesondere für Sprachassistenten, interaktive Dialogsysteme und Live-Übersetzungen von Vorteil ist. Im Gegensatz zu herkömmlichen API-Aufrufen, die sequentiell abgearbeitet werden, ermöglicht diese Technologie eine kontinuierliche, bidirektionale Kommunikation zwischen Nutzer und KI, wodurch Gesprächsverläufe natürlicher und spontaner wirken.
Insbesondere bei der Entwicklung barrierefreier Anwendungen spielt die Realtime API eine Schlüsselrolle. Menschen mit Seh- oder Schreibbehinderungen können durch die nahtlose Sprachverarbeitung einfacher mit digitalen Systemen interagieren, indem sie Sprachbefehle verwenden oder sich Textinhalte in Echtzeit vorlesen lassen. Sie eröffnet auch neue Möglichkeiten im Kundenservice, indem sie dynamische, KI-gesteuerte Chatbots und Telefonassistenten unterstützt, die sofort auf Kundenanfragen reagieren können.
Technologisch kombiniert die Realtime API mehrere fortschrittliche Komponenten der Sprach-KI. Die Multimodalität ermöglicht eine flexible Kombination von Text- und Sprachverarbeitung und damit Anwendungen, die dynamisch zwischen gesprochener und geschriebener Kommunikation wechseln können. Darüber hinaus verbessert die Unterstützung von Funktionsaufrufen die Integration externer Dienste, so dass Sprachassistenten beispielsweise nicht nur Fragen beantworten, sondern auch direkt Aktionen ausführen können, etwa eine Reservierung im Restaurant oder eine Erinnerung im Kalender.
Mit o1 (aktuell bereits o3), das im September 2024 veröffentlicht wurde, geht OpenAI einen weiteren Schritt in Richtung Künstliche Allgemeine Intelligenz (AGI). Das Modell beeindruckt durch fortgeschrittene logische Schlussfolgerungen und herausragende Leistungen in Mathematik, Programmierung und Naturwissenschaften. Zunächst nur als Preview-Modell („o1-preview“ und „o1-mini“) verfügbar, wurde es am 5. Dezember 2024 offiziell eingeführt - inklusive einer leistungsstärkeren Pro-Version. Auch andere Anbieter verfügen mittlerweile über leistungsstarke Reasoning Modelle, wie Anthropic mit Claude 4.0 Opus und Google mit Gemini 2.5 (Pro).
Besonders spannend: Diese Modelle sind bereits in Anwendungen wie GitHub Copilot, Cursor, Windsurf etc. integriert, was seine Praxistauglichkeit unterstreicht.
Hierbei handelt es sich um durchaus komplexe Themen, die eine ausführliche Darstellung verdienen, aber im Rahmen dieses eher fachlichen Artikels im Folgenden nur kurz angerissen werden. Mit dem zunehmenden Einsatz von LLMs werden neben den technologischen und anwendungsbezogenen Aspekten daher auch eine Reihe ethischer und rechtlicher Fragen diskutiert. Ein zentrales Thema ist dabei z.B. der Umgang mit Bias: Da LLMs auf umfangreichen Textkorpora aus dem Internet trainiert werden, übernehmen sie unweigerlich auch die darin eventuell enthaltenen gesellschaftlichen Vorurteile, Diskriminierungen oder stereotypen Darstellungen. Diese können sich subtil in den Antworten niederschlagen - etwa in geschlechtsspezifischen Rollenzuschreibungen oder bei sensiblen Themen wie Herkunft, Religion oder politischer Einstellung. Natürlich ist die Beurteilung und eine eventuelle Korrektur dieser Sachverhalte wiederum äußerst individuell und schwierig. Hier lassen sich auch deutliche Unterschiede zwischen den einzelnen Herstellern im Umgang damit feststellen. Während z.B. eine Firma wie Anthropic (Claude) versucht, hier möglichst “korrekt” vorzugehen, liegt der Fokus bei xAI (Grok) auf einer durch nachträgliche Korrektur “unverfälschten” Darstellung der Ergebnisse.
Ein weiteres zentrales Thema ist der Datenschutz, da in den Trainingsdaten potentiell auch personenbezogene oder sensible Informationen enthalten sein können, die unbeabsichtigt in den generierten Ausgaben wieder auftauchen. Zunehmend wird auch diskutiert, ob Urheberrechte verletzt werden, wenn LLMs auf der Basis von urheberrechtlich geschützten Texten trainiert werden und daraus Inhalte generieren, die sich stilistisch oder inhaltlich stark an das Original anlehnen. Dies ist nicht nur bei der Textgenerierung relevant, sondern auch bei der Erzeugung von Bildern und Sounds (schreibe/zeichne/komponiere mir im Stil von..).
Diese Herausforderungen machen deutlich, dass der Einsatz von LLM nicht nur eine technische, sondern auch eine gesellschaftliche und rechtliche Verantwortung mit sich bringt. In der Europäischen Union wird derzeit mit dem AI Act ein umfassender Rechtsrahmen geschaffen, der die Entwicklung und Anwendung von KI-Systemen regulieren soll. Der Gesetzesentwurf sieht unter anderem Transparenzpflichten, Risikoabschätzungen und klare Anforderungen an die Datenqualität - insbesondere für sogenannte Hochrisikoanwendungen - vor.
Hier gibt es deutliche Unterschiede in der Herangehensweise zwischen der EU und den USA, die auch auf dem KI-Gipfel in Paris Anfang 2025 deutlich wurden. Während in den USA die Chancen der KI-Entwicklung im Vordergrund stehen (Rede von J.D. Vance), die man sich nicht durch Überregulierung verbauen will, ist der Fokus der EU eher auf Regulierung gerichtet. Welcher Ansatz hier “besser” ist, kann derzeit nicht abschließend beurteilt werden.
Für Entwickler, Anbieter und Anwender von LLMs vor allem in der EU bedeutet dies: Der rechtssichere und verantwortungsvolle Umgang mit diesen Technologien wird in Zukunft nicht nur erwartet, sondern auch gesetzlich gefordert. Wer LLMs einsetzen will, muss daher nicht nur ihre Funktionsweise verstehen, sondern auch ihre Auswirkungen im gesellschaftlichen Kontext reflektieren und entsprechende Vorkehrungen treffen.
Dieser Text ist ein Versuch, einen kurzen, nicht-technischen Überblick über die Entwicklung, Funktionsweise und Einsatzmöglichkeiten von Large Language Models (LLMs) zu geben. Dabei soll vor allem aufgezeigt werden, wie sich die Sprachverarbeitung in den letzten Jahrzehnten von regelbasierten Ansätzen und statistischen Sprachmodellen hin zur Transformer-Architektur entwickelt hat.
Ein zentrales Ergebnis dieser Entwicklung ist die Entstehung von GPT-Modellen als speziellem Typ von LLMs, die ausschließlich auf einem Decoder basieren und Texte autoregressiv erzeugen. Durch das Training mit Milliarden von Parametern und den Einsatz moderner Hardwareplattformen haben GPTs ein beachtliches Maß an Sprachkompetenz erreicht - sei es beim Verstehen von Texten, beim Beantworten von Fragen oder beim Generieren kreativer Inhalte.
Viele Innovationen wie Chain-of-Thought-Reasoning, KI-Agenten, die Integration externer Wissensquellen (RAG), Echtzeit-Sprachverarbeitung und der Weg in Richtung künstliche allgemeine Intelligenz (AGI) verdeutlichen dies: Die Entwicklung von LLMs ist noch lange nicht abgeschlossen, sondern befindet sich in einem dynamischen Fortschrittsprozess.
Gerade deshalb ist es wichtig zu betonen, dass das Themenfeld rund um LLMs und GPTs einem rasanten Wandel unterliegt. Neue Modellvarianten, optimierte Trainingsmethoden, regulatorische Rahmenbedingungen und gesellschaftliche Anforderungen verändern den Stand der Technik kontinuierlich. Dieses Dokument bietet daher eine Momentaufnahme - einen Einstieg zum Verständnis, aber keine abschließende Darstellung. Wer mit LLM arbeitet oder ihre Auswirkungen verstehen will, muss bereit sein, sich regelmäßig über neue Entwicklungen zu informieren und vorhandenes Wissen ständig zu hinterfragen und zu aktualisieren.
Für das tiefere Verständnis der Funktionsweise von LLMs kann ich sehr
Hands-On Large Language Models
Language Understanding and Generationvon Jay Allmmar und Maarten Grootendorst (erschienen bei O’Reilly)
empfehlen. Das Buch verwendet aufschlussreiche Grafiken und viele Python Beispiele um an das Thema heranzuführen. Daneben gibt es eine Vielzahl von weiteren - auch deutschsprachigen Ressourcen (geprüfte KI Recherche):
Bücher:
Ertel, Wolfgang: Grundkurs Künstliche Intelligenz: Eine praxisorientierte Einführung. Springer Vieweg, 5. Auflage, 2021. https://link.springer.com/book/10.1007/978-3-658-32075-1
Lee, Kai-Fu & Chen, Qiufan: KI 2041: Zehn Zukunftsvisionen. Campus Verlag, 2022. https://www.campus.de/buecher-campus-verlag/wirtschaft-gesellschaft/wirtschaft/ki_2041-17112.html
Online-Ressourcen:
KI-Campus - Die Lernplattform für Künstliche Intelligenz: https://ki-campus.org/
DFKI - Deutsches Forschungszentrum für Künstliche Intelligenz: https://www.dfki.de/
Bücher:
Raschka, Sebastian: Machine Learning und KI kompakt. dpunkt.verlag, 2025. https://dpunkt.de/produkt/machine-learning-und-ki-kompakt/
Paaß, Gerhard & Giesselbach, Sven: Foundation Models for Natural Language Processing. Springer, 2023. https://link.springer.com/book/10.1007/978-3-031-23190-2
Online-Ressourcen:
Empfehlung: Sebastian Raschkas Blog: https://sebastianraschka.com/
Heise c't: "KI: So funktionieren künstliche Sprachsysteme vom Typ 'Transformer'": https://www.heise.de/hintergrund/KI-So-funktionieren-kuenstliche-Sprachsysteme-vom-Typ-Transformer-7077832.html
TU Darmstadt - NLP Ressourcen: https://www.informatik.tu-darmstadt.de/ukp/ukp_home/index.en.jsp
Bücher:
Stricker, Hans-Peter: Sprachmodelle verstehen: Chatbots und generative künstliche Intelligenz im Zusammenhang. Springer, 2024. https://link.springer.com/book/10.1007/978-3-662-68280-7
Online-Ressourcen:
DataScientest: "Das Word Embedding": https://datascientest.com/de/word-embedding
SKOPOS Elements: "Word Embeddings - Die Revolution der Sprachverarbeitung": https://skopos-elements.de/wissen/blog/maschinelles-lernen/word-embeddings
TU München - Natural Language Processing Projektwoche: https://www.ce.cit.tum.de/ldv/lehre/natural-language-processing-projektwoche/
Bücher:
Stricker, Hans-Peter: Sprachmodelle verstehen: Chatbots und generative künstliche Intelligenz im Zusammenhang. Springer, 2024. https://link.springer.com/book/10.1007/978-3-662-68280-7
Online-Ressourcen:
Studyflix: "Wie funktioniert ChatGPT?": https://studyflix.de/informatik/wie-funktioniert-chatgpt-6771
Neuroflash Blog: "GPT-Chat: Ein umfassender Leitfaden für Anfänger": https://neuroflash.com/de/blog/entdecke-wie-gptchat-funktioniert/
Deutsche Nationalbibliothek Blog: "Neue Wege mit großen Sprachmodellen?": https://blog.dnb.de/neue-wege-mit-grossen-sprachmodellen/
Online-Ressourcen:
Fraunhofer IESE Blog: "Was sind Large Language Models?": https://www.iese.fraunhofer.de/blog/large-language-models-ki-sprachmodelle/
SEEBURGER Blog: "Lebenslanges Lernen für KI-Sprachmodelle": https://blog.seeburger.com/learning-is-a-lifelong-task-also-for-ai-language-models/
Business Insider: "Kostenlose KI-Kurse": https://www.businessinsider.de/karriere/hype-um-chat-gpt-sieben-kostenlose-online-kurse-von-experten-von-amazon-meta-und-co-ueber-kuenstliche-intelligenz-in-der-arbeitswelt/
Bücher:
Fessler, Roman & Denz, Alexander: ChatGPT 2025 - Das große Benutzerhandbuch. 2024. https://www.amazon.de/ChatGPT-2025-Benutzerhandbuch-verständlich-Prompting-Techniken/dp/3903491837
Bock, Oliver & Knust, Florian: Das inoffizielle ChatGPT Handbuch: In 3 Tagen zum KI-Profi. 2024. https://www.amazon.de/Das-inoffizielle-ChatGPT-Handbuch-KI-Profi/dp/B0D5HZY3DR
Hattenhauer, Rainer: ChatGPT & Co.: Wie du KI richtig nutzt. Rheinwerk Verlag, 2024. https://www.rheinwerk-verlag.de/chatgpt-und-co-wie-du-ki-richtig-nutzt/
Online-Kurse:
Fraunhofer: "Kompakteinstieg: Prompting für Generative KI": https://www.bigdata-ai.fraunhofer.de/de/data-scientist/schulungssuche/KompakteinstiegPromptingFuerGenerativeKI.html
121WATT: "Prompt-Engineering-Seminar": https://www.121watt.de/seminare/prompt-engineering-seminar/
AKADEMIE HERKERT: "ChatGPT Prompt Engineer": https://www.akademie-herkert.de/themenuebersicht/kuenstliche-intelligenz/prompt-engineer-fuer-chatgpt
Google Cloud: "Anleitung: Prompt Engineering für KI": https://cloud.google.com/discover/what-is-prompt-engineering
Vergleiche und Übersichten:
moinAI: "Die Top LLMs im Vergleich": https://www.moin.ai/en/chatbot-wiki/large-language-models-llms
Hilker Consulting: "Large Language Models (LLM)": https://hilker-consulting.de/blog/ki/kuenstliche-intelligenz-large-language-models-llm/
ZDFheute: "Welches KI-Sprachmodell ist das beste?": https://www.zdf.de/nachrichten/wissen/kuenstliche-intelligenz-ki-sprachmodell-vergleich-100.html
Ressourcen:
LAION: "LeoLM - Ein Impuls für Deutschsprachige LLM-Forschung": https://laion.ai/blog-de/leo-lm/
Fraunhofer IESE: "Open Source Large Language Models selbst betreiben": https://www.iese.fraunhofer.de/blog/open-source-large-language-models-selbst-betreiben/
BigData Insider: "Large Language Models – Open Source als Alternative?": https://www.bigdata-insider.de/large-language-models-open-source-als-alternative-a-b68917c61b72f26d28c30780d3dc8117/
HuggingFace - Deutsche Modelle: https://huggingface.co/models?language=de
Bücher:
Bartneck, Christoph et al.: Ethik in KI und Robotik. Carl Hanser Verlag, 2019. [https://www.
Vieweg, Stefan H.: KI für das Gute: Künstliche Intelligenz und Ethik. Springer, 2023. https://link.springer.com/book/10.1007/978-3-031-22777-6
Online-Ressourcen:
LfDI Baden-Württemberg: "Rechtsgrundlagen im Datenschutz beim Einsatz von KI": https://www.baden-wuerttemberg.datenschutz.de/rechtsgrundlagen-datenschutz-ki/
IHK München: "Datenschutz & Künstliche Intelligenz": https://www.ihk-muenchen.de/de/Service/Recht-und-Steuern/Datenschutz/ki/
Datenschutz-Generator: "KI-Verordnung (KI-VO) - Ratgeber": https://datenschutz-generator.de/ki-verordnung/
DFKI - Ethische KI: https://www.dfki.de/en/web/research/research-departments/educational-technology-lab/ethische-inklusive-und-verantwortungsvolle-ki
Online-Ressourcen:
KI-Campus Blog: "Chain of Thought Prompting": https://ki-campus.org/blog/chain-of-thought-prompting
AI-United: "Retrieval Augmented Generation": https://www.ai-united.de/retrieval-augmented-generation/
Elements of AI (Deutsche Version): https://www.elementsofai.de/
Cyber Valley: https://cyber-valley.de/
Max-Planck-Institut für Intelligente Systeme: https://is.mpg.de/
KI-Campus - Die Lernplattform für Künstliche Intelligenz: https://ki-campus.org/
UNIDIGITAL: "Kostenfreie KI-Kurse im Überblick": https://www.unidigital.news/kostenfreie-ki-kurse-im-ueberblick/
Ein erfahrenes Entwicklerteam, das mit Leib und Seele Software erstellt.
![]()
Brunnstr. 25,
Regensburg
+49 (941) 94592-0
+49 (941) 94592-22